<!-- Thanks for creating a PR! To make it easier for reviewers and
everyone else to understand what your changes relate to, please add some
relevant content to the headings below. Feel free to ignore or delete
sections that you don't think are relevant. Thank you! ❤️ -->
Introduces 2 new endpoints (behind flag `projectScopedStickiness` to set
and get the setting
## About the changes
<!-- Describe the changes introduced. What are they and why are they
being introduced? Feel free to also add screenshots or steps to view the
changes if they're visual. -->
<!-- Does it close an issue? Multiple? -->
Closes #
<!-- (For internal contributors): Does it relate to an issue on public
roadmap? -->
<!--
Relates to [roadmap](https://github.com/orgs/Unleash/projects/10) item:
#
-->
### Important files
<!-- PRs can contain a lot of changes, but not all changes are equally
important. Where should a reviewer start looking to get an overview of
the changes? Are any files particularly important? -->
## Discussion points
<!-- Anything about the PR you'd like to discuss before it gets merged?
Got any questions or doubts? -->
---------
Signed-off-by: andreas-unleash <andreas@getunleash.ai>
### What
This patches two very subtle bugs in the proxy repository that cause it
to never actually stop polling the db in the background
## Details - Issue 1
We've recently started to get the following output when running `yarn
test`:
` Attempted to log "Error: Unable to acquire a connection
at Object.queryBuilder
(/home/simon/dev/unleash/node_modules/knex/lib/knex-builder/make-knex.js:111:26)`
This seems to occur for every test suite after running the proxy tests
and the full stack trace doesn't point to anything related to the
running tests that produce this output. Running a `git bisect` points to
this commit:
6e44a65c58
being the culprit but I believe that this may have surfaced the bug
rather than causing it.
Layering in a few console logs and running Unleash, seems to point to
the proxy repository setting up data polling but never actually
terminating it when `stop` was called, which is inline with the output
here - effectively the tests were continuing to run the polling in the
background after the suite had exited and jest freaks out that an async
task is running when it shouldn't be. This is easy to reproduce once the
console logs are in place in the `dataPolling` function, by running
Unleash - creating and deleting a front end token never terminates the
poll cycle.
I believe the cause here is some subtlety around using async functions
with timers - stop was being called, which results in the timer being
cleared but a scheduled async call was already on the stack, causing the
recursive call to resolve after stop, resurrecting the timer and
reinitializing the poll cycle.
I've moved the terminating code into the async callback. Which seems to
solve the problem here.
## Details - Issue 2
Related to the first issue, when the proxy service stops the underlying
Unleash Client, it never actually calls destroy on the client, it only
removes it from its internal map. That in turn means that the Client
never calls stop on the injected repository, it only removes it from
memory. However, the scheduled task is `async` and `unref`, meaning it
continues to spin in the background until every other process also
exits. This is patched by simply calling destroy on the client when
cleaning up
## The Ugly
This is really hard to test effectively, mostly because this is an issue
caused by internals within NodeJS and async. I've added a test that
reads the output from the debug log (and also placed a debug log in the
termination code). This also requires the test code to wait until the
async task completes. This is horribly fragile so if someone has a
better idea on how to prove this I would be a very happy human.
The second ugly part is that this is a subtle issue in complex code that
really, really needs to work correctly. I'm nervous about making changes
here without lots of eyes on this
The patched test is currently depending on runtime to take more than a
millisecond to update the tested property. That's not always true and
more so on a fast machine, which makes this test flakey. This forces the
old timestamp to be 100 ms in the past so that the checked property must be at least 100 ms different if the update occurred
<!-- Thanks for creating a PR! To make it easier for reviewers and
everyone else to understand what your changes relate to, please add some
relevant content to the headings below. Feel free to ignore or delete
sections that you don't think are relevant. Thank you! ❤️ -->
- Create UpdateTagsSchema
- Create PUT endpoint
## About the changes
<!-- Describe the changes introduced. What are they and why are they
being introduced? Feel free to also add screenshots or steps to view the
changes if they're visual. -->
<!-- Does it close an issue? Multiple? -->
Relates to#
https://linear.app/unleash/issue/1-767/refactor-existing-tag-component-to-also-allow-removing-tags
<!-- (For internal contributors): Does it relate to an issue on public
roadmap? -->
<!--
Relates to [roadmap](https://github.com/orgs/Unleash/projects/10) item:
#
-->
### Important files
<!-- PRs can contain a lot of changes, but not all changes are equally
important. Where should a reviewer start looking to get an overview of
the changes? Are any files particularly important? -->
## Discussion points
<!-- Anything about the PR you'd like to discuss before it gets merged?
Got any questions or doubts? -->
---------
Signed-off-by: andreas-unleash <andreas@getunleash.ai>
## About the changes
client-metrics-schema is less strict than proxy-metrics-schema because
the former allows empty `instanceId` and also supports dates as
timestamps as well as date-formatted strings.
Using the same schema makes sense to reduce maintainability costs and
it's less error-prone if we need to modify the schema because underlying
the schema they both use the same code.
The reasoning is that proxy metrics should align with our client
metrics. Alternatively, we have new endpoints for edge metrics that will
aggregate and bucket by client.

## Discussion points
Will we ever want to evolve proxy-metrics differently than
client-metrics? I'm under the assumption that the answer is no
### What
Change /edge/metrics endpoint to accept list of ClientMetricsEnv
### Rationale
We originally made the assumption that we probably didn't need to keep
splitting from a map of features into ClientMetricsEnv for bulk, instead
the bulk poster could post ClientMetricsEnv directly. However, Unleash
still expected the old client metrics format with a dictionary of
featurename -> metricsForFeature. This PR changes that to now accept the
list of ClientMetricsEnv (preprocessed data from downstream) instead of
expecting metrics to be in the old single application metric format.
This makes the distinction from the event services clearer.
In enterprise we'll also rename LoginEventService etc to reflect this
rename.
In addition this adds a setting for how long of a retention one should have, defaulting to 336 hours (2 weeks)
## About the changes
Documentation about feature toggle variants per environment
## Discussion points
The version when this will be available is still to be defined.
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.ai>
<!-- Thanks for creating a PR! To make it easier for reviewers and
everyone else to understand what your changes relate to, please add some
relevant content to the headings below. Feel free to ignore or delete
sections that you don't think are relevant. Thank you! ❤️ -->
## About the changes
<!-- Describe the changes introduced. What are they and why are they
being introduced? Feel free to also add screenshots or steps to view the
changes if they're visual. -->
Define and implements Project api token permissions
Assign permissions to existing roles
Adjust UI to support them
Adjust BE to implement
---------
Signed-off-by: andreas-unleash <andreas@getunleash.ai>
Co-authored-by: Fredrik Strand Oseberg <fredrik.no@gmail.com>
## About the changes
Promoted experimental networkView flag into a configuration that relies
on prometheusApi being configured.
Also, a follow-up on https://github.com/Unleash/unleash/pull/3054 moving
this code to enterprise because it doesn't make sense to maintain this
code in OSS where it's not being used.
## About the changes
Implementation of bulk metrics and registration endpoint. This will be
used by edge nodes to send all collected information.
Types around metrics were improved and `IClientApp.bucket` with type
`any` is no longer needed
---------
Co-authored-by: sighphyre <liquidwicked64@gmail.com>
## About the changes
Spotted some issues in logs:
```json
{
"level":"warn",
"message":"Failed to store \"feature-environment-variants-updated\" event: error: insert into \"events\" (\"created_by\", \"data\", \"environment\", \"feature_name\", \"pre_data\", \"project\", \"tags\", \"type\") values (DEFAULT, $1, $2, $3, $4, $5, $6, $7) returning \"id\", \"type\", \"created_by\", \"created_at\", \"data\", \"pre_data\", \"tags\", \"feature_name\", \"project\", \"environment\" - null value in column \"created_by\" violates not-null constraint",
"name":"lib/db/event-store.ts"
}
```
In all other events we're doing the following:
b7fdcd36c0/src/lib/services/segment-service.ts (L80)
So this is just mimicking that to quickly release a patch, but I'll look
into a safer (type-checked) solution so this problem does not happen
again
## About the changes
This PR prepares the GA of service accounts: OpenAPI tags, documentation
and flag removal
Relates to [roadmap](https://github.com/orgs/Unleash/projects/10) item:
#2942
---------
Co-authored-by: Nuno Góis <github@nunogois.com>
Batch Metrics as a capability developed to support the frontend API to
handle more metrics from SDKs without overloading the DB to much. It has
been running in Unleash Cloud for months and has proven to work quite
nice.
This PR simply removes the flag to make the capability GA, also for
self-hosted users.
## About the changes
While trying to count only features that are not archived to display the
amount of features of a project, accidentally we filtered out projects
with all features archived (they should show up in the list but with
count of features zero)
This PR takes the project status API a step further by adding the
capability of providing a date to control the selection. We are
currently making calculations based on a gliding 30 day window, updated
once a day. The initial database structure and method for updating the
UI is outlined in this PR.
## About the changes
This PR adds two new functions that is protected by CR. When used
instead of the current setVariantOnEnv and setVariantsOnEnv if the flag
UNLEASH_EXPERIMENTAL_CR_ON_VARIANTS is set, the call is blocked. This
leaves the old functions, which is used from the CR flow in place, and
adds new methods protected by CR.
Also adds e2e tests verifying that the methods will block requests if CR
is enabled for project:environment pair, as well as not block if CR is
not enabled. Tests already in place should confirm that the default
flow, without the flag enabled just works.
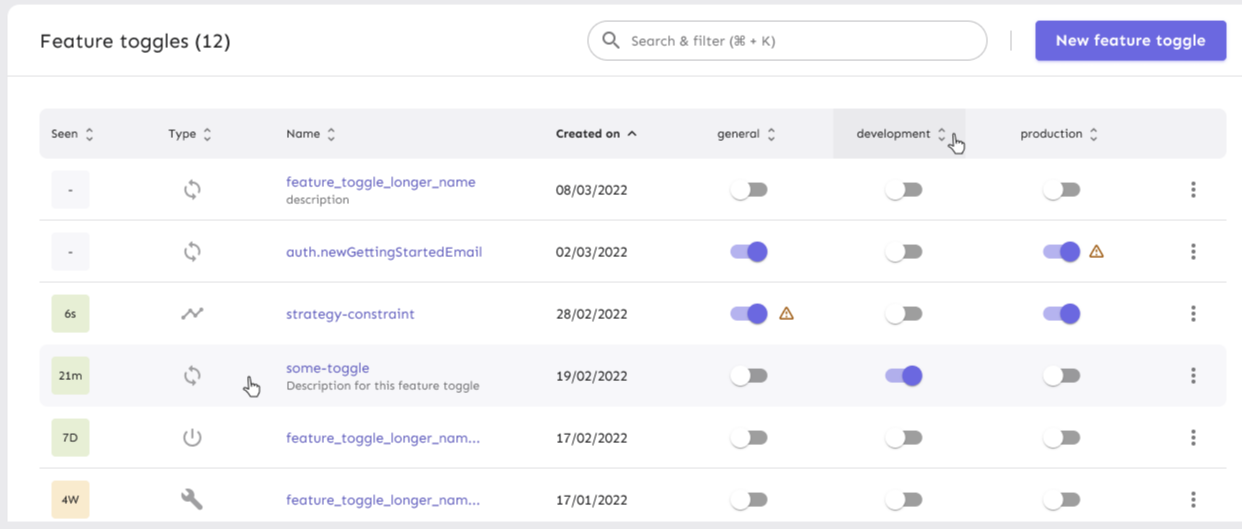
## About the changes
Add warnings when we detect something might be wrong with the customer
configuration, in particular with regard to variants configuration
## Rationale
Moving from variants per feature to variants per environment will allow
users to have fine-grained permissions and more control over variants on
different environments: #2254
But because this requires an additional step of copying variants to
other environments, we identified the potential risk of users forgetting
to follow this step. To keep them informed about this, we're introducing
a warning sign after a toggle is enabled when we detect that:
1. The environment is enabled without variants
2. Other enabled environments have variants
This situation would be a problem if you rely on `getVariant` method
from the SDK, because without variants you'll receive the default
variant. Probably, not what you'd expect after enabling the toggle, but
there are situations where this might be correct. Because of the latter,
we thought that adding a warning and letting the user handle the
situation was the best solution.
## UI sketches

Co-authored-by: Nuno Góis <github@nunogois.com>
{kind=link}
{kind=link}
{kind=link}