Updates the instance stats endpoint with
- maxEnvironmentStrategies
- maxConstraints
- maxConstraintValues
It adds the following rows to the front end table:
- segments (already in the payload, just not used for the table before)
- API tokens (separate rows for type, + one for total) (also existed
before, but wasn't listed)
- Highest number of strategies used for a single flag in a single
environment
- Highest number of constraints used on a single strategy
- Highest number of values used for a single constraint

Turns out we've been trying to return API token data in instance stats
for a while, but that the serialization has failed. Serializing a JS map
just yields an empty object.
This PR fixes that serialization and also adds API tokens to the
instance stats schema (it wasn't before, but we did return it). Adding
it to the schema is also part of making resource usage visible as part
of the soft limits project.
Hooks up the new project read model and updates the existing project
service to use it instead when the flag is on.
In doing:
- creates a composition root for the read model
- includes it in IUnleashStores
- updates some existing methods to accept either the old or the new
model
- updates the OpenAPI schema to deprecate the old properties
Adds an endpoint to return all event creators.
An interesting point is that it does not return the user object, but
just created_by as a string. This is because we do not store user IDs
for events, as they are not strictly bound to a user object, but rather
a historical user with the name X.
Previously people were able to send random data to feature type. Now it
is validated.
Fixes https://github.com/Unleash/unleash/issues/7751
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
Changed the url of event search to search/events to align with
search/features. With that created a search controller to keep all
searches under there.
Added first test.
https://linear.app/unleash/issue/2-2439/create-new-integration-events-endpointhttps://linear.app/unleash/issue/2-2436/create-new-integration-event-openapi-schemas
This adds a new `/events` endpoint to the Addons API, allowing us to
fetch integration events for a specific integration configuration id.
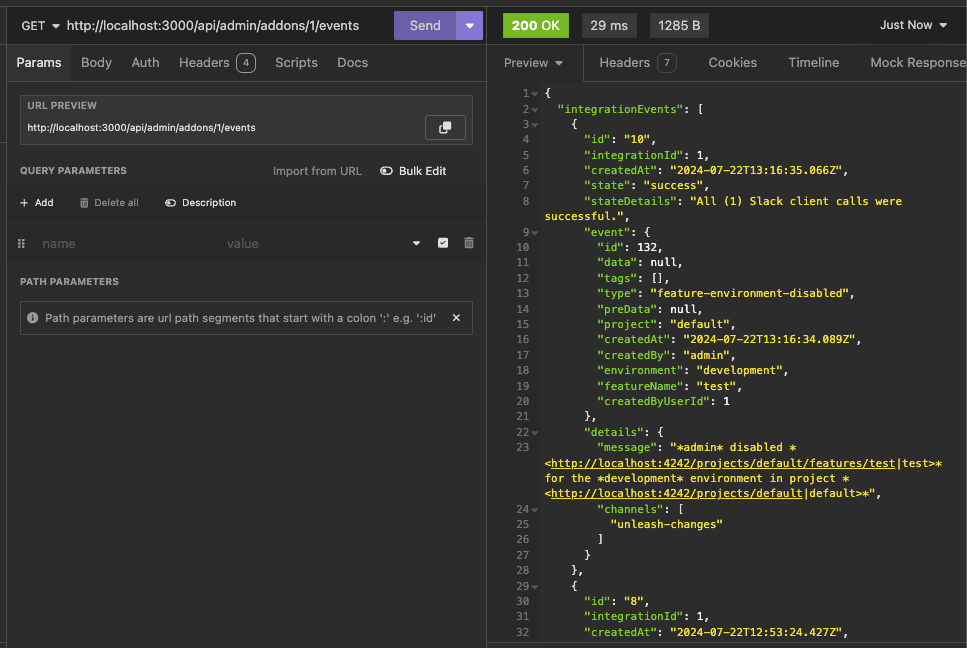
Also includes:
- `IntegrationEventsSchema`: New schema to represent the response object
of the list of integration events;
- `yarn schema:update`: New `package.json` script to update the OpenAPI
spec file;
- `BasePaginationParameters`: This is copied from Enterprise. After
merging this we should be able to refactor Enterprise to use this one
instead of the one it has, so we don't repeat ourselves;
We're also now correctly representing the BIGSERIAL as BigInt (string +
pattern) in our OpenAPI schema. Otherwise our validation would complain,
since we're saying it's a number in the schema but in fact returning a
string.
https://linear.app/unleash/issue/2-2453/validate-patched-data-against-schema
This adds schema validation to patched data, fixing potential issues of
patching data to an invalid state.
This can be easily reproduced by patching a strategy constraints to be
an object (invalid), instead of an array (valid):
```sh
curl -X 'PATCH' \
'http://localhost:4242/api/admin/projects/default/features/test/environments/development/strategies/8cb3fec6-c40a-45f7-8be0-138c5aaa5263' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '[
{
"path": "/constraints",
"op": "replace",
"from": "/constraints",
"value": {}
}
]'
```
Unleash will accept this because there's no validation that the patched
data actually looks like a proper strategy, and we'll start seeing
Unleash errors due to the invalid state.
This PR adapts some of our existing logic in the way we handle
validation errors to support any dynamic object. This way we can perform
schema validation with any object and still get the benefits of our
existing validation error handling.
This PR also takes the liberty to expose the full instancePath as
propertyName, instead of only the path's last section. We believe this
has more upsides than downsides, especially now that we support the
validation of any type of object.

This PR adds a feature flag limit to Unleash. It's set up to be
overridden in Enterprise, where we turn the limit up.
I've also fixed a couple bugs in the fake feature flag store.
This adds an extended metrics format to the metrics ingested by Unleash
and sent by running SDKs in the wild. Notably, we don't store this
information anywhere new in this PR, this is just streamed out to
Victoria metrics - the point of this project is insight, not analysis.
Two things to look out for in this PR:
- I've chosen to take extend the registration event and also send that
when we receive metrics. This means that the new data is received on
startup and on heartbeat. This takes us in the direction of collapsing
these two calls into one at a later point
- I've wrapped the existing metrics events in some "type safety", it
ain't much because we have 0 type safety on the event emitter so this
also has some if checks that look funny in TS that actually check if the
data shape is correct. Existing tests that check this are more or less
preserved
This PR adds the back end for API token resource limits.
It adds the limit to the schema and checks the limit in the service.
## Discussion points
The PAT service uses a different service and different store entirely,
so I have not included testing any edge cases where PATs are included.
However, that could be seen as "knowing too much". We could add tests
that check both of the stores in tandem, but I think it's overkill for
now.
This PR updates the Unleash UI to use the new environment limit.
As it turns out, we already had an environment limit in the UI, but it
was hardcoded (luckily, its value is the same as the new default value
🥳).
In addition to the existing places this limit was used, it also disables
the "new environment" button if you've reached the limit. Because this
limit already exists, I don't think we need a flag for it. The only
change is that you can't click a button (that should be a link!) that
takes you to a page you can't do anything on.
This PR adds limits for environments to the resource limit schema. The
actual limiting will have to be done in Enterprise, however, so this is
just laying the groundwork.
This PR fixes how Unleash handles tag values. Specifically, it does
these things:
1. Trims leading and trailing whitespace from tag values before
inserting them into the database
2. Updates OpenAPI validation to not allow whitespace-only and to ignore
leading and trailing whitespace
Additionally, it moves the tag length constants into the constants file
from the Joi tag schema file. This is because importing the values
previously rendered them as undefined (probably due to a circular
dependency somewhere in the system). This means that the previous values
were also ignored by OpenAPI.
UI updates reflecting this wil follow.
## Background
When you tag a flag, there's nothing stopping you from using an entirely
empty tag or a tag with leading/trailing whitespace.
Empty tags make little sense and leading trailing whitespace differences
are incredibly subtle:

Additionally, leading and trailing whitespace is not shown in the
dropdown list, so you'd have to guess at which is the right one.

## About the changes
Removes the deprecated state endpoint, state-service (despite the
service itself not having been marked as deprecated), and the file
import in server-impl. Leaves a TODO in place of where file import was
as traces for a replacement file import based on the new import/export
functionality
1. Added new schema and tests
2. Controller also accepts the data
3. Also sending fake data from frontend currently
Next steps, implement service/store layer and frontend
This PR expands upon #6773 by returning the list of removed properties
in the API response. To achieve this, I added a new top-level `warnings`
key to the API response and added an `invalidContextProperties` property
under it. This is a list with the keys that were removed.
## Discussion points
**Should we return the type of each removed key's value?** We could
expand upon this by also returning the type that was considered invalid
for the property, e.g. `invalidProp: 'object'`. This would give us more
information that we could display to the user. However, I'm not sure
it's useful? We already return the input as-is, so you can always
cross-check. And the only type we allow for non-`properties` top-level
properties is `string`. Does it give any useful info? I think if we want
to display this in the UI, we might be better off cross-referencing with
the input?
**Can properties be invalid for any other reason?** As far as I can
tell, that's the only reason properties can be invalid for the context.
OpenAPI will prevent you from using a type other than string for the
context fields we have defined and does not let you add non-string
properties to the `properties` object. So all we have to deal with are
top-level properties. And as long as they are strings, then they should
be valid.
**Should we instead infer the diff when creating the model?** In this
first approach, I've amended the `clean-context` function to also return
the list of context fields it has removed. The downside to this approach
is that we need to thread it through a few more hoops. Another approach
would be to compare the input context with the context used to evaluate
one of the features when we create the view model and derive the missing
keys from that. This would probably work in 98 percent of cases.
However, if your result contains no flags, then we can't calculate the
diff. But maybe that's alright? It would likely be fewer lines of code
(but might require additional testing), although picking an environment
from feels hacky.
Adds a bearer token middleware that adds support for tokens prefixed
with "Bearer" scheme. Prefixing with "Bearer" is optional and the old
way of authenticating still works, so we now support both ways.
Also, added as part of our OpenAPI spec which now displays authorization
as follows:

Related to #4630. Doesn't fully close the issue as we're still using
some invalid characters for the RFC, in particular `*` and `[]`
For safety reasons this is behind a feature flag
---------
Co-authored-by: Gastón Fournier <gaston@getunleash.io>
This change fixes the OpenAPI schema to disallow non-string properties
on the top level of the context (except, of course, the `properties`
object).
This means that we'll no longer be seeing issues with rendering
invalid contexts, because we don't accept them in the first place.
This solution comes with some tradeoffs discussed in the [PR](https://github.com/Unleash/unleash/pull/6676). Following on from that, this solution isn't optimal, but it's a good stop gap. A better solution (proposed in the PR discussion) has been added as an idea for future projects.
The bulk of the discussion around the solution is included here for reference:
@kwasniew:
Was it possible to pass non string properties with our UI before?
Is there a chance that something will break after this change?
@thomasheartman:
Good question and good looking out 😄
You **could** pass non-string, top-level properties into the API before. In other words, this would be allowed:
```js
{
appName: "my-app",
nested: { object: "accepted" }
}
```
But notably, non-string values under `properties` would **not** be accepted:
```js
{
appName: "my-app",
properties: {
nested: { object: "not accepted" }
}
}
```
**However**, the values would not contribute to the evaluation of any constraints (because their type is invalid), so they would effectively be ignored.
Now, however, you'll instead get a 400 saying that the "nested" value must be a string.
I would consider this a bug fix because:
- if you sent a nested object before, it was most likely an oversight
- if you sent the nested object on purpose, expecting it to work, you would be perplexed as to why it didn't work, as the API accepted it happily
Furthermore, the UI will also tell you that the property must be a string now if you try to do it from the UI.
On the other hand, this does mean that while you could send absolute garbage in before and we would just ignore it, we don't do that anymore. This does go against how we allow you to send anything for pretty much all other objects in our API.
However, the SDK context is special. Arbitrary keys aren't ignored, they're actually part of the context itself and as such should have a valid value.
So if anything breaks, I think it breaks in a way that tells you why something wasn't working before. However, I'd love to hear your take on it and we can re-evaluate whether this is the right fix, if you think it isn't.
@kwasniew:
Coming from the https://en.wikipedia.org/wiki/Robustness_principle mindset I'm thinking if ignoring the fields that are incorrect wouldn't be a better option. So we'd accept incorrect value and drop it instead of:
* failing with client error (as this PR) or
* saving incorrect value (as previous code we had)
@thomasheartman:
Yeah, I considered that too. In fact, that was my initial idea (for the reason you stated). However, there's a couple tradeoffs here (as always):
1. If we just ignore those values, the end user doesn't know what's happened unless they go and dig through the responses. And even then, they don't necessarily know why the value is gone.
2. As mentioned, for the context, arbitrary keys can't be ignored, because we use them to build the context. In other words, they're actually invalid input.
Now, I agree that you should be liberal in what you accept and try to handle things gracefully, but that means you need to have a sensible default to fall back to. Or, to quote the Wikipedia article (selectively; with added emphasis):
> programs that receive messages should accept non-conformant input **as long as the meaning is clear**.
In this case, the meaning isn't clear when you send extra context values that aren't strings.
For instance, what's the meaning here:
```js
{
appName: "my-app",
nested: { object: "accepted", more: { further: "nesting" } }
}
```
If you were trying to use the `nested` value as an object, then that won't work. Ideally, you should be alerted.
Should we "unwind" the object and add all string keys as context values? That doesn't sound very feasible **or** necessarily like the right thing.
Did you just intend to use the `appName` and for the `nested` object to be ignored?
And it's because of this caveat that I'm not convinced just ignoring the keys are the right thing to do. Because if you do, the user never knows they were ignored or why.
----
**However**, I'd be in favor of ignoring they keys if we could **also** give the users warnings at the same time. (Something like what we do in the CR api, right? Success with warnings?)
If we can tell the user that "we ignored the `a`, `b`, and `c` keys in the context you sent because they are invalid values. Here is the result of the evaluation without taking those keys into account: [...]", then I think that's the ideal solution.
But of course, the tradeoff is that that increases the complexity of the API and the complexity of the task. It also requires UI adjustments etc. This means that it's not a simple fix anymore, but more of a mini-project.
But, in the spirit of the playground, I think it would be a worthwhile thing to do because it helps people learn and understand how Unleash works.
This PR adds a property issues to application schema, and also adds all
the missing features that have been reported by SDK, but do not exist in
Unleash.
In order to prevent users from being able to assign roles/permissions
they don't have, this PR adds a check that the user performing the
action either is Admin, Project owner or has the same role they are
trying to grant/add.
This addAccess method is only used from Enterprise, so there will be a
separate PR there, updating how we return the roles list for a user, so
that our frontend can only present the roles a user is actually allowed
to grant.
This adds the validation to the backend to ensure that even if the
frontend thinks we're allowed to add any role to any user here, the
backend can be smart enough to stop it.
We should still update frontend as well, so that it doesn't look like we
can add roles we won't be allowed to.
Fixes ##5799 and #5785
When you do not provide a token we should resolve to the "default"
environment to maintain backward compatibility. If you actually provide
a token we should prefer that and even block the request if it is not
valid.
An interesting fact is that "default" environment is not available on a
fresh installation of Unleash. This means that you need to provide a
token to actually get access to toggle configurations.
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
Created a build script that generates orval schemas with automatic
cleanup. Also generating new ones.
1. yarn gen:api **(generates schemas)**
2. rm -rf src/openapi/apis **(remove apis)**
3. sed -i '1q' src/openapi/index.ts **(remove all rows except first)**
This PR adds an endpoint to Unleash that accepts an error message and
option error stack and logs it as an error. This allows us to leverage
errors in logs observability to catch UI errors consistently.
Considered a test, but this endpoint only accepts and logs input, so I'm
not sure how useful it would be.
Adds a new Inactive Users list component to admin/users for easier cleanup of users that are counted as inactive: No sign of activity (logins or api token usage) in the last 180 days.
---------
Co-authored-by: David Leek <david@getunleash.io>
This backwards compatible change allows us to specify a schema `id`
(full path) which to me feels a bit better than specifying the schema
name as a string, since a literal string is prone to typos.
### Before
```ts
requestBody: createRequestSchema(
'createResourceSchema',
),
responses: {
...getStandardResponses(400, 401, 403, 415),
201: resourceCreatedResponseSchema(
'resourceSchema',
),
},
```
### After
```ts
requestBody: createRequestSchema(
createResourceSchema.$id,
),
responses: {
...getStandardResponses(400, 401, 403, 415),
201: resourceCreatedResponseSchema(
resourceSchema.$id,
),
},
```
## About the changes
Adds the new nullable column created_by_user_id to the data used by
feature-tag-store and feature-tag-service. Also updates openapi schemas.
I noticed I was getting warnings logged in my local instance when
visiting the users page (`/admin/users`)
```json
{
"schema": "#/components/schemas/publicSignupTokensSchema",
"errors": [
{
"instancePath": "/tokens/0/users/0/username",
"schemaPath": "#/components/schemas/userSchema/properties/username/type",
"keyword": "type",
"params": {
"type": "string"
},
"message": "must be string"
}
]
}
```
It was complaining because one of my users doesn't have a username, so
the value returned from the API was:
```json
{
"users": [
{
"id": 2,
"name": "2mas",
"username": null
}
]
}
```
This adjustment fixes that oversight by allowing `null` values for the
username.
### What
Adds `createdByUserId` to all events exposed by unleash. In addition
this PR updates all tests and usages of the methods in this codebase to
include the required number.
This change adds a property to the segmentStrategiesSchema to make sure
that change request strategies are listed in the openapi spec
It also renames the files that contains that schema and its tests from
`admin-strategies-schema` to `segment-strategies-schema`.