This PR fixes an issue where the personal dashboard would fail to render
if the flag was called `.` (Curiously, it was not an issue with `..`;
probably because they end up accessing different URLs).
I've taken the very pragmatic approach here of saying "right, we know
that `.` and `..` cause issues, let's just not even try to fetch data
for them".
The option, of course, is to bake in more error handling in the
components, but due to how we've got hooks depending on each other, it's
a bit of a rabbit hole to go down. I think this is a good compromise for
now.
So now, you'll get this instead:

I've also gone and updated the text for when we get a metrics fetching
error, because this probably isn't due to the flag name anymore. If it
is, we want to know.
This PR:
- conditionally deprecates the project health report endpoint. We only
use this for technical debt dashboard that we're removing. Now it's
deprecated once you turn the simplifiy flag on.
- extracts the calculate project health function into the project health
functions file in the appropriate domain folder. That same function is
now shared by the project health service and the project status service.
For the last point, it's a little outside of how we normally do things,
because it takes its stores as arguments, but it slots in well in that
file. An option would be to make a project health read model and then
wire that up in a couple places. It's more code, but probably closer to
how we do things in general. That said, I wanted to suggest this because
it's quick and easy (why do much work when little work do trick?).
This PR updates the project status service (and schemas and UI) to use
the project's current health instead of the 4-week average.
I nabbed the `calculateHealthRating` from
`src/lib/services/project-health-service.ts` instead of relying on the
service itself, because that service relies on the project service,
which relies on pretty much everything in the entire system.
However, I think we can split the health service into a service that
*does* need the project service (which is used for 1 of 3 methods) and a
service (or read model) that doesn't. We could then rely on the second
one for this service without too much overhead. Or we could extract the
`calculateHealthRating` into a shared function that takes its stores as
arguments. ... but I suggest doing that in a follow-up PR.
Because the calculation has been tested other places (especially if we
rely on a service / shared function for it), I've simplified the tests
to just verify that it's present.
I've changed the schema's `averageHealth` into an object in case we want
to include average health etc. in the future, but this is up for debate.
This change updates the "view unhealthy flags" link in the project
status sidebar to use the correct filter. The previous link was put in
before we had a filter for potentially stale, so this updates the link
to use that filter.
This PR fixes the counting of unhealthy flags for the project status
page. The issue was that we were looking for `archived = false`, but we
don't set that flag in the db anymore. Instead, we set the `archived_at`
date, which should be null if the flag is unarchived.
**This migration introduces a query that calculates the licensed user
counts and inserts them into the licensed_users table.**
**The logic ensures that:**
1. All users created up to a specific date are included as active users
until they are explicitly deleted.
2. Deleted users are excluded after their deletion date, except when
their deletion date falls within the last 30 days or before their
creation date.
3. The migration avoids duplicating data by ensuring records are only
inserted if they don’t already exist in the licensed_users table.
**Logic Breakdown:**
**Identify User Events (user_events):** Extracts email addresses from
user-related events (user-created and user-deleted) and tracks the type
and timestamp of the event. This step ensures the ability to
differentiate between user creation and deletion activities.
**Generate a Date Range (dates):** Creates a continuous range of dates
spanning from the earliest recorded event up to the current date. This
ensures we analyze every date, even those without events.
**Determine Active Users (active_emails):** Links dates with user events
to calculate the status of each email address (active or deleted) on a
given day. This step handles:
- The user's creation date.
- The user's deletion date (if applicable).
**Calculate Daily Active User Counts (result):**
For each date, counts the distinct email addresses that are active based
on the conditions:
- The user has no deletion date.
- The user's deletion date is within the last 30 days relative to the
current date.
- The user's creation date is before the deletion date.
This PR adds the option to select potentially stale flags from the UI.
It also updates the name we use for parsing from the API: instead of
`potentiallyStale` we use `potentially-stale`. This follows the
precedent set by "kill switch" (which we send as 'kill-switch'), the
only other multi-word option that I could find in our filters.
This PR adds support for the `potentiallyStale` value in the feature
search API. The value is added as a third option for `state` (in
addition to `stale` and `active`). Potentially stale is a subset of
active flags, so stale flags are never considered potentially stale,
even if they have the flag set in the db.
Because potentially stale is a separate column in the db, this
complicates the query a bit. As such, I've created a specialized
handling function in the feature search store: if the query doesn't
include `potentiallyStale`, handle it as we did before (the mapping has
just been moved). If the query *does* contain potentially stale, though,
the handling is quite a bit more involved because we need to check
multiple different columns against each other.
In essence, it's based on this logic:
when you’re searching for potentially stale flags, you should only get flags that are active and marked as potentially stale. You should not get stale flags.
This can cause some confusion, because in the db, we don’t clear the potentially stale status when we mark a flag as stale, so we can get flags that are both stale and potentially stale.
However, as a user, if you’re looking for potentially stale flags, I’d be surprised to also get (only some) stale flags, because if a flag is stale, it’s definitely stale, not potentially stale.
This leads us to these six different outcomes we need to handle when your search includes potentially stale and stale or active:
1. You filter for “potentially stale” flags only. The API will give you only flags that are active and marked as potentially stale. You will not get stale flags.
2. You filter only for flags that are not potentially stale. You will get all flags that are active and not potentially stale and all stale flags.
3. You search for “is any of stale, potentially stale”. This is our “unhealthy flags” metric. You get all stale flags and all flags that are active and potentially stale
4. You search for “is none of stale, potentially stale”: This gives you all flags that are active and not potentially stale. Healthy flags, if you will.
5. “is any of active, potentially stale”: you get all active flags. Because we treat potentially stale as a subset of active, this is the same as “is active”
6. “is none of active, potentially stale”: you get all stale flags. As in the previous point, this is the same as “is not active”
This change adds a db migration to make the potentially_stale column
non-nullable. It'll set any NULL values to `false`.
In the down-migration, make the column nullable again.
## About the changes
- Remove `idNumberMiddleware` method and change to use `parameters`
field in `openApiService.validPath` method for the flexibility.
- Remove unnecessary `Number` type converting method and change them to
use `<{id: number}>` to specify the type.
### Reference
The changed response looks like the one below.
```JSON
{
"id":"8174a692-7427-4d35-b7b9-6543b9d3db6e",
"name":"BadDataError",
"message":"Request validation failed: your request body or params contain invalid data. Refer to the `details` list for more information.",
"details":[
{
"message":"The `/params/id` property must be integer. You sent undefined.",
"path":"/params/id"
}
]
}
```
I think it might be better to customize the error response, especially
`"You sent undefined."`, on another pull request if this one is
accepted. I prefer to separate jobs to divide the context and believe
that it helps reviewer easier to understand.
Remove everything related to the connected environment count for project
status. We decided that because we don't have anywhere to link it to at
the moment, we don't want to show it yet.
## About the changes
Builds on top of #8766 to use memoized results from stats-service.
Because stats service depends on version service, and to avoid making
the version service depend on stats service creating a cyclic
dependency. I've introduced a telemetry data provider. It's not clean
code, but it does the job.
After validating this works as expected I'll clean up
Added an e2e test validating that the replacement is correct:
[8475492](847549234c)
and it did:
https://github.com/Unleash/unleash/actions/runs/11861854341/job/33060032638?pr=8776#step:9:294
Finally, cleaning up version service
## About the changes
Our stats are used for many places and many times to publish prometheus
metrics and some other things.
Some of these queries are heavy, traversing all tables to calculate
aggregates.
This adds a feature flag to be able to memoize 1 minute (by default) how
long to keep the calculated values in memory.
We can use the key of the function to individually control which ones
are memoized or not and for how long using a numeric variant.
Initially, this will be disabled and we'll test in our instances first
This PR fixes a number of keyboard accessibility issues with the
feedback sidebar. They are (in no particular order):
1. The radio inputs don't have a focus style for `focus-visible` (when
keyboard focused).
2. There's two close buttons there for some reason? One is invisible,
but you can tab to it?
3. The sidebar doesn't trap focus, so you can tab out of the modal and
continue tabbing through the main page (with the modal still open)
4. The sidebar doesn't steal focus. When you open it, your focus remains
on the button you used to open it. So if you want to navigate to it, you
have to go through the entire page (behind the modal) to get to it.
5. The sidebar can't be closed by 'escape'.
The fixes are:
1. Apply the same styles when focus visible as when hover
2. Wrap the component in the `BaseModal` component
3. Wrap the component in the `BaseModal` component
4. Wrap the component in the `BaseModal` component
5. Wrap the component in the `BaseModal` component
(see a theme here?)
Additionally, because the base modal has its own `open` state, I removed
the wrapping conditionally render, reducing nesting by one stop. Most of
the changes in the file are just whitespace changes.
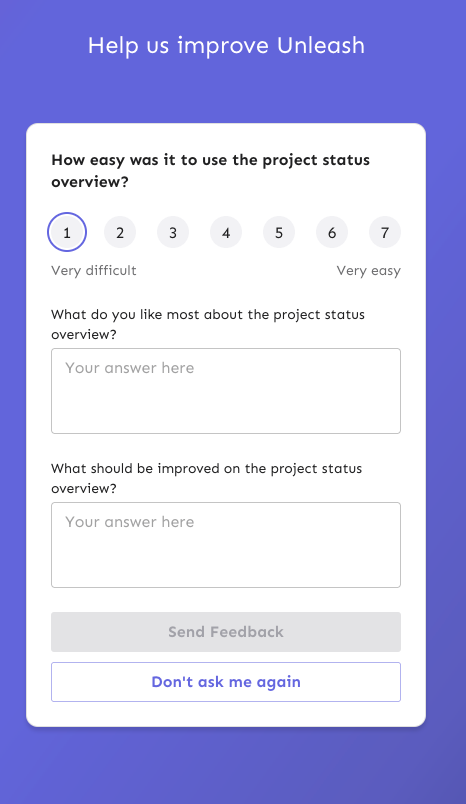
I considered also applying an auto-focus to the first input in the
sidebar, but our linter doesn't like it. Additionally MDN lists the
following [accessibility
concerns](https://developer.mozilla.org/en-US/docs/Web/HTML/Global_attributes/autofocus#accessibility_concerns)
> Automatically focusing a form control can confuse visually-impaired
people using screen-reading technology and people with cognitive
impairments. When autofocus is assigned, screen-readers "teleport" their
user to the form control without warning them beforehand.
>
> Use careful consideration for accessibility when applying the
autofocus attribute. Automatically focusing on a control can cause the
page to scroll on load. The focus can also cause dynamic keyboards to
display on some touch devices. While a screen reader will announce the
label of the form control receiving focus, the screen reader will not
announce anything before the label, and the sighted user on a small
device will equally miss the context created by the preceding content.
So I'll leave it off.
Refetch actionable change requests whenever you perform an action on a
change request. This ensures that the change request notifications are
up-to-date for you. Of course, it can still get out of sync if someone
else performs an action on the change request, but that's more of an
edge case.
This change makes it so that the project status sidebar will close
when you follow a link within it. We do that by using JS event
bubbling and attaching a handler on the modal parent. We can listen
for events and check whether the target is an anchor and, if so, close
the modal.