Clearing onboarding tables, because the data is invalid and we want to
start tracking all of this for only new customers.
This migration must be applied after the new logic is implemented.
We are observing incorrect data in Prometheus, which is consistently
non-reproducible. After a restart, the issue does not occur, but if the
pods run for an extended period, they seem to enter a strange state
where the counters become entangled and start sharing arbitrary values
that are added to the counters.
For example, the `feature_lifecycle_stage_entered` counter gets an
arbitrary value, such as 12, added when `inc()` is called. The
`exceedsLimitErrorCounter` shows the same behavior, and the code
implementation is identical.
We also tested some existing `increase()` counters, and they do not
suffer from this issue.
All calls to `counter.labels(labels).inc(`) will be replaced by
`counter.increment()` to try to mitigate the issue.
Previously we expected the tag to look like `type:value`. Now we allow
everything after first colon, as the value and not break query
`type:this:still:is:value`.
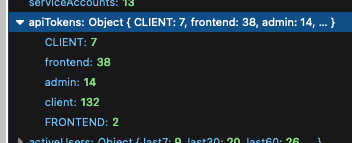
Fixes a bug where if you had API keys using different casing for the
same type, they'd come out as different types in the API token count
map. To get around it, we normalize the keys to lowercase before
inserting them into the map, taking into account any previous values
that might have existed for that type.
Should fix issues like this:
Updates the instance stats endpoint with
- maxEnvironmentStrategies
- maxConstraints
- maxConstraintValues
It adds the following rows to the front end table:
- segments (already in the payload, just not used for the table before)
- API tokens (separate rows for type, + one for total) (also existed
before, but wasn't listed)
- Highest number of strategies used for a single flag in a single
environment
- Highest number of constraints used on a single strategy
- Highest number of values used for a single constraint

Turns out we've been trying to return API token data in instance stats
for a while, but that the serialization has failed. Serializing a JS map
just yields an empty object.
This PR fixes that serialization and also adds API tokens to the
instance stats schema (it wasn't before, but we did return it). Adding
it to the schema is also part of making resource usage visible as part
of the soft limits project.
Path types in our openapi are inferred as string (which is a sensible
default). But we can be more specific and provide the right type for
each parameter. This is one example of how we can do that
This PR fixes an issue where the number of flags belonging to a project
was wrong in the new getProjectsForAdminUi.
The cause was that we now join with the events table to get the most
"lastUpdatedAt" data. This meant that we got multiple rows for each
flag, so we counted the same flag multiple times. The fix was to use a
"distinct".
Additionally, I used this as an excuse to write some more tests that I'd
been thinking about. And in doing so also uncovered another bug that
would only ever surface in verrry rare conditions: if a flag had been
created in project A, but moved to project B AND the
feature-project-change event hadn't fired correctly, project B's last
updated could show data from that feature in project A.
I've also taken the liberty of doing a little bit of cleanup.
## About the changes
When storing last seen metrics we no longer validate at insert time that
the feature exists. Instead, there's a job cleaning up on a regular
interval.
Metrics for features with more than 255 characters, makes the whole
batch to fail, resulting in metrics being lost.
This PR helps mitigate the issue while also logs long name feature names
{kind=link}