We are changing how the Delta API works, as discussed:
1. We have removed the `updated` and `removed` arrays and now keep
everything in the `events` array.
2. We decided to keep the hydration cache separate from the events array
internally. Since the hydration cache has a special structure and may
contain not just one feature but potentially 1,000 features, it behaved
differently, requiring a lot of special logic to handle it.
3. Implemented `nameprefix` filtering, which we were missing before.
Things still to implement:
1. Segment hydration and updates to it.
Our delta API was returning archived feature as updated. Now making sure
we do not put `archived-feature `event into `updated` event array.
Also stop returning removed as complex object.
This PR updates the project status service (and schemas and UI) to use
the project's current health instead of the 4-week average.
I nabbed the `calculateHealthRating` from
`src/lib/services/project-health-service.ts` instead of relying on the
service itself, because that service relies on the project service,
which relies on pretty much everything in the entire system.
However, I think we can split the health service into a service that
*does* need the project service (which is used for 1 of 3 methods) and a
service (or read model) that doesn't. We could then rely on the second
one for this service without too much overhead. Or we could extract the
`calculateHealthRating` into a shared function that takes its stores as
arguments. ... but I suggest doing that in a follow-up PR.
Because the calculation has been tested other places (especially if we
rely on a service / shared function for it), I've simplified the tests
to just verify that it's present.
I've changed the schema's `averageHealth` into an object in case we want
to include average health etc. in the future, but this is up for debate.
Remove everything related to the connected environment count for project
status. We decided that because we don't have anywhere to link it to at
the moment, we don't want to show it yet.
This PR adds stale flag count to the project status payload. This is
useful for the project status page to show the number of stale flags in
the project.
This PR adds a project lifecycle read model file along with the most
important (and most complicated) query that runs with it: calculating
the average time spent in each stage.
The calculation relies on the following:
- when calculating the average of a stage, only flags who have gone into
a following stage are taken into account.
- we'll count "next stage" as the next row for the same feature where
the `created_at` timestamp is higher than the current row
- if you skip a stage (go straight to live or archived, for instance),
that doesn't matter, because we don't look at that.
The UI only shows the time spent in days, so I decided to go with
rounding to days directly in the query.
## Discussion point:
This one uses a subquery, but I'm not sure it's possible to do without
it. However, if it's too expensive, we can probably also cache the value
somehow, so it's not calculated more than every so often.
This PR adds member, api token, and segment counts to the project status
payload. It updates the schemas and adds the necessary stores to get
this information. It also adds a new query to the segments store for
getting project segments.
I'll add tests in a follow-up.
This PR wires up the connectedenvironments data from the API to the
resources widget.
Additionally, it adjusts the orval schema to add the new
connectedEnvironments property, and adds a loading state indicator for
the resource values based on the project status endpoint response.
As was discussed in a previous PR, I think this is a good time to update
the API to include all the information required for this view. This
would get rid of three hooks, lots of loading state indicators (because
we **can** do them individually; check out
0a334f9892)
and generally simplify this component a bit.
Here's the loading state:

This PR adds connected environments to the project status payload.
It's done by:
- adding a new `getConnectedEnvironmentCountForProject` method to the
project store (I opted for this approach instead of creating a new view
model because it already has a `getEnvironmentsForProject` method)
- adding the project store to the project status service
- updating the schema
For the schema, I opted for adding a `resources` property, under which I
put `connectedEnvironments`. My thinking was that if we want to add the
rest of the project resources (that go in the resources widget), it'd
make sense to group those together inside an object. However, I'd also
be happy to place the property on the top level. If you have opinions
one way or the other, let me know.
As for the count, we're currently only counting environments that have
metrics and that are active for the current project.
Adding project status schema definition, controller, service, e2e test.
Next PR will add functionality for activity object.
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
Archived features can be searched now.
This is the backend and small parts of frontend preparing to add
filters, buttons etc in next PR.
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
https://linear.app/unleash/issue/2-2787/add-openai-api-key-to-our-configuration
Adds the OpenAI API key to our configuration and exposes a new
`unleashAIAvailable` boolean in our UI config to let our frontend know
that we have configured this. This can be used together with our flag to
decide whether we should enable our experiment for our users.
This PR fixes a bug where the default project would have no listed
owners. The issue was that the default project has no user owners by
default, so we didn't get a result back when looking for user owners.
Now we check whether we have any owners for that project, and if we
don't, then we return the system user as an owner instead.
This also fixes an issue for the default project where you have no roles
(because by default, you don't) by updating the schema to allow an empty
list.
This PR contains a number of small updates to the dashboard schemas,
including rewording descriptions, changing numbers to integers, setting
minimum values.
This PR hooks up the owners and admins of Unleash to the UI. They'll
only be visible in cases where you have no projects.
In addition, it adds Orval schemas for the new payload properties and
updates the generating schemas to fix some minor typing issues.
Adds Unleash admins to the personal dashboard payload.
Uses the access store (and a new method) to fetch admins and maps it to
a new `MinimalUser` type. We already have a `User` class, but it
contains a lot of information we don't care about here, such as `isAPI`,
SCIM data etc.
In the UI, admins will be shown to users who are not part of any
projects. This is the default state for new viewer users, and can also
happen for editors if you archive the default project, for instance.
Tests in a follow-up PR
This PR adds all user-type owners of projects that you have access to to
the personal dashboard payload. It adds the new `projectOwners` property
regardless of whether you have access to any projects or not because it
required less code and fewer conditionals, but we can do the filtering
if we want to.
To add the owners, it uses the private project checker to get accessible
projects before passing those to the project owner read model, which has
a new method to fetch user owners for projects.
This PR adds project owner information to the personal dashboard's
project payload.
To do so, it uses the existing project owners read model.
I've had to make a few changes to the project owners read model to
accomodate this:
- make the input type to `addOwners` more lenient. We only need the
project ids, so we can make that the only required property
- fall back to using email as the name if the user has no name or
username (such as if you sign up with the demo auth)
This PR adds some of the necessary project data to the personal
dashboard API: project names and ids, and the roles that the user has in
each of these projects.
I have not added project owners yet, as that would increase the
complexity a bit and I'd rather focus on that in a separate PR.
I have also not added projects you are part of through a group, though I
have added a placeholder test for that. I will address this in a
follow-up.
https://linear.app/unleash/issue/2-2664/implement-event-tooltips
Implements event tooltips in the new event timeline.
This leverages our current `feature-event-formatter-md` to provide both
a label and a summary of the event. Whenever our new `eventTimeline`
flag is enabled, we enrich our events in our event search endpoint with
this information. We've discussed different options here and reached the
conclusion that this is the best path forward for now. This way we are
being consistent, DRY, relatively performant and it also gives us a
happy path forward if we decide to scope in the event log revamp, since
this data will already be present there.
We also added a new `label` property to each of our event types
currently in our event formatter. This way we can have a concise,
human-readable name for each event type, instead of exposing the
internal event type string.
~~We also fixed the way the event formatter handled bold text (as in,
**bold**). Before, it was wrapping them in *single asterisks*, but now
we're using **double asterisks**. We also abstracted this away into a
helper method aptly named `bold`. Of course, this change meant that a
bunch of snapshots and tests needed to be updated.~~
~~This new `bold` method also makes it super easy to revert this
decision if we choose to, for any reason. However I believe we should
stick with markdown formatting, since it is the most commonly supported
formatting syntax, so I see this as an important fix. It's also in the
name of the formatter (`md`). I also believe bold was the original
intent. If we want italic formatting we should implement it separately
at a later point.~~
Edit: It was _bold_ of me to assume this would work out of the box on
Slack. It does when you manually try it on the app, but not when using
the Slack client. See: https://github.com/Unleash/unleash/pull/8222


Previously we expected the tag to look like `type:value`. Now we allow
everything after first colon, as the value and not break query
`type:this:still:is:value`.
Updates the instance stats endpoint with
- maxEnvironmentStrategies
- maxConstraints
- maxConstraintValues
It adds the following rows to the front end table:
- segments (already in the payload, just not used for the table before)
- API tokens (separate rows for type, + one for total) (also existed
before, but wasn't listed)
- Highest number of strategies used for a single flag in a single
environment
- Highest number of constraints used on a single strategy
- Highest number of values used for a single constraint

Turns out we've been trying to return API token data in instance stats
for a while, but that the serialization has failed. Serializing a JS map
just yields an empty object.
This PR fixes that serialization and also adds API tokens to the
instance stats schema (it wasn't before, but we did return it). Adding
it to the schema is also part of making resource usage visible as part
of the soft limits project.
Hooks up the new project read model and updates the existing project
service to use it instead when the flag is on.
In doing:
- creates a composition root for the read model
- includes it in IUnleashStores
- updates some existing methods to accept either the old or the new
model
- updates the OpenAPI schema to deprecate the old properties
Adds an endpoint to return all event creators.
An interesting point is that it does not return the user object, but
just created_by as a string. This is because we do not store user IDs
for events, as they are not strictly bound to a user object, but rather
a historical user with the name X.
Previously people were able to send random data to feature type. Now it
is validated.
Fixes https://github.com/Unleash/unleash/issues/7751
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
Changed the url of event search to search/events to align with
search/features. With that created a search controller to keep all
searches under there.
Added first test.
https://linear.app/unleash/issue/2-2439/create-new-integration-events-endpointhttps://linear.app/unleash/issue/2-2436/create-new-integration-event-openapi-schemas
This adds a new `/events` endpoint to the Addons API, allowing us to
fetch integration events for a specific integration configuration id.
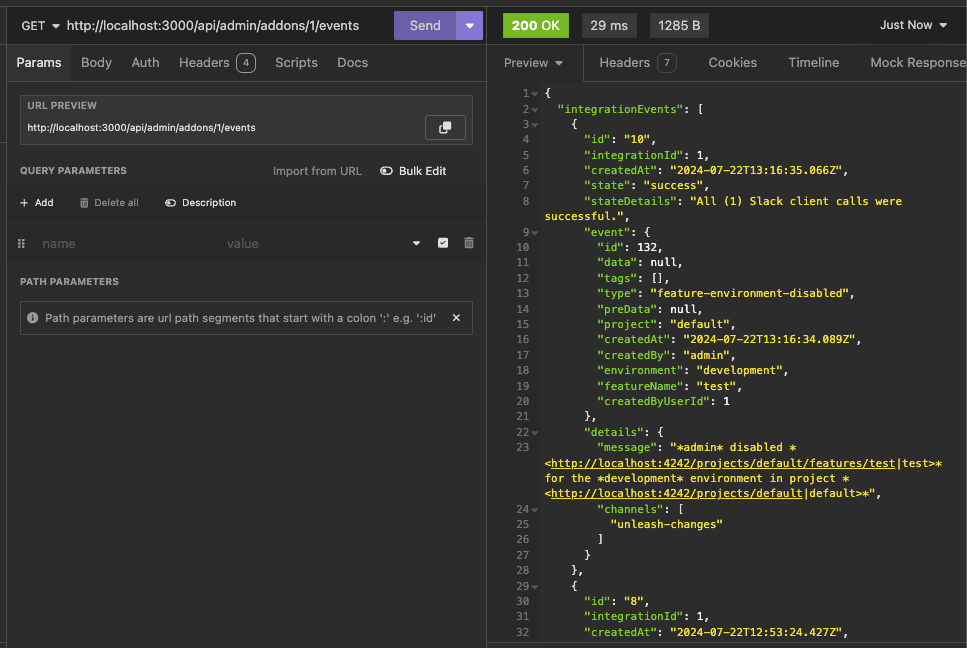
Also includes:
- `IntegrationEventsSchema`: New schema to represent the response object
of the list of integration events;
- `yarn schema:update`: New `package.json` script to update the OpenAPI
spec file;
- `BasePaginationParameters`: This is copied from Enterprise. After
merging this we should be able to refactor Enterprise to use this one
instead of the one it has, so we don't repeat ourselves;
We're also now correctly representing the BIGSERIAL as BigInt (string +
pattern) in our OpenAPI schema. Otherwise our validation would complain,
since we're saying it's a number in the schema but in fact returning a
string.
https://linear.app/unleash/issue/2-2453/validate-patched-data-against-schema
This adds schema validation to patched data, fixing potential issues of
patching data to an invalid state.
This can be easily reproduced by patching a strategy constraints to be
an object (invalid), instead of an array (valid):
```sh
curl -X 'PATCH' \
'http://localhost:4242/api/admin/projects/default/features/test/environments/development/strategies/8cb3fec6-c40a-45f7-8be0-138c5aaa5263' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '[
{
"path": "/constraints",
"op": "replace",
"from": "/constraints",
"value": {}
}
]'
```
Unleash will accept this because there's no validation that the patched
data actually looks like a proper strategy, and we'll start seeing
Unleash errors due to the invalid state.
This PR adapts some of our existing logic in the way we handle
validation errors to support any dynamic object. This way we can perform
schema validation with any object and still get the benefits of our
existing validation error handling.
This PR also takes the liberty to expose the full instancePath as
propertyName, instead of only the path's last section. We believe this
has more upsides than downsides, especially now that we support the
validation of any type of object.

This PR adds a feature flag limit to Unleash. It's set up to be
overridden in Enterprise, where we turn the limit up.
I've also fixed a couple bugs in the fake feature flag store.
This adds an extended metrics format to the metrics ingested by Unleash
and sent by running SDKs in the wild. Notably, we don't store this
information anywhere new in this PR, this is just streamed out to
Victoria metrics - the point of this project is insight, not analysis.
Two things to look out for in this PR:
- I've chosen to take extend the registration event and also send that
when we receive metrics. This means that the new data is received on
startup and on heartbeat. This takes us in the direction of collapsing
these two calls into one at a later point
- I've wrapped the existing metrics events in some "type safety", it
ain't much because we have 0 type safety on the event emitter so this
also has some if checks that look funny in TS that actually check if the
data shape is correct. Existing tests that check this are more or less
preserved
This PR adds the back end for API token resource limits.
It adds the limit to the schema and checks the limit in the service.
## Discussion points
The PAT service uses a different service and different store entirely,
so I have not included testing any edge cases where PATs are included.
However, that could be seen as "knowing too much". We could add tests
that check both of the stores in tandem, but I think it's overkill for
now.
This PR updates the Unleash UI to use the new environment limit.
As it turns out, we already had an environment limit in the UI, but it
was hardcoded (luckily, its value is the same as the new default value
🥳).
In addition to the existing places this limit was used, it also disables
the "new environment" button if you've reached the limit. Because this
limit already exists, I don't think we need a flag for it. The only
change is that you can't click a button (that should be a link!) that
takes you to a page you can't do anything on.
This PR adds limits for environments to the resource limit schema. The
actual limiting will have to be done in Enterprise, however, so this is
just laying the groundwork.
This PR fixes how Unleash handles tag values. Specifically, it does
these things:
1. Trims leading and trailing whitespace from tag values before
inserting them into the database
2. Updates OpenAPI validation to not allow whitespace-only and to ignore
leading and trailing whitespace
Additionally, it moves the tag length constants into the constants file
from the Joi tag schema file. This is because importing the values
previously rendered them as undefined (probably due to a circular
dependency somewhere in the system). This means that the previous values
were also ignored by OpenAPI.
UI updates reflecting this wil follow.
## Background
When you tag a flag, there's nothing stopping you from using an entirely
empty tag or a tag with leading/trailing whitespace.
Empty tags make little sense and leading trailing whitespace differences
are incredibly subtle:

Additionally, leading and trailing whitespace is not shown in the
dropdown list, so you'd have to guess at which is the right one.
