We do some validation on flag names, but there's some cases that slip
through. These are some cases that we should handle better.
With `..` as a name, you can't go into the flag in Unleash and you can't
activate any environments because the it is interpreted as "go up a
level".
## About the changes
We have many aggregation queries that run on a schedule:
f63496d47f/src/lib/metrics.ts (L714-L719)
These staticCounters are usually doing db query aggregations that
traverse tables and we run all of them in parallel:
f63496d47f/src/lib/metrics.ts (L410-L412)
This can add strain to the db. This PR suggests a way of handling these
queries in a more structured way, allowing us to run them sequentially
(therefore spreading the load):
f02fe87835/src/lib/metrics-gauge.ts (L38-L40)
As an additional benefit, we get both the gauge definition and the
queries in a single place:
f02fe87835/src/lib/metrics.ts (L131-L141)
This PR only tackles 1 metric, and it only focuses on gauges to gather
initial feedback. The plan is to migrate these metrics and eventually
incorporate more types (e.g. counters)
---------
Co-authored-by: Nuno Góis <github@nunogois.com>
Give the ability to change when users are considered inactive via an
environment variable `USER_INACTIVITY_THRESHOLD_IN_DAYS` or
configuration option: `userInactivityThresholdInDays`. Default remains
180 days
## About the changes
This fixes#8029. How to reproduce the issue is in the ticket.
The issue happens because when a web app is hosted in the same domain as
Unleash UI and the web app uses unleash SDK to make requests to Unleash,
the browser automatically includes the cookie in the request headers,
because:
- The request URL matches the cookie's Path attribute (which it does in
this case).
- The request is sent to the same domain (which it is, since both apps
are under the same domain).
And this is by design in the HTTP cookie specification:
https://datatracker.ietf.org/doc/html/rfc6265
This PR avoids overriding the API user with the session user if there's
already an API user in the request. It's an alternative to
https://github.com/Unleash/unleash/pull/8434Closes#8029
This gives us better types for our wrapTimer function.
Maybe the type `(args: any) => any` could also be improved
---------
Co-authored-by: Nuno Góis <nuno@getunleash.io>
https://linear.app/unleash/issue/2-2787/add-openai-api-key-to-our-configuration
Adds the OpenAI API key to our configuration and exposes a new
`unleashAIAvailable` boolean in our UI config to let our frontend know
that we have configured this. This can be used together with our flag to
decide whether we should enable our experiment for our users.
This PR fixes a bug where the default project would have no listed
owners. The issue was that the default project has no user owners by
default, so we didn't get a result back when looking for user owners.
Now we check whether we have any owners for that project, and if we
don't, then we return the system user as an owner instead.
This also fixes an issue for the default project where you have no roles
(because by default, you don't) by updating the schema to allow an empty
list.
This PR contains a number of small updates to the dashboard schemas,
including rewording descriptions, changing numbers to integers, setting
minimum values.
This property does not seem to be used anywhere, so we can remove it.
Can't find any references in code here or in enterprise. Let's try it
and see if it breaks.
This PR updates the personal dashboard project endpoint to return owners
and roles. It also adds the impl for getting roles (via the access
store).
I'm filtering the roles for a project to only include project roles for
now, but we might wanna change this later.
Tests and UI update will follow.
This PR is part 1 of returning project owners and your project roles for
the personal dashboard single-project endpoint.
It moves the responsibility of adding owners and roles to the project to
the service from the controller and adds a new method to the project
owners read model to take care of it.
I'll add roles and tests in follow-up PRs.
Splitting #8271 into smaller pieces. This first PR will focus on making
access service handle empty string inputs gracefully and converting them
to null before inserting them into the database.
This PR hooks up the owners and admins of Unleash to the UI. They'll
only be visible in cases where you have no projects.
In addition, it adds Orval schemas for the new payload properties and
updates the generating schemas to fix some minor typing issues.
This PR adds tests for the new admins property of the personal dashboard
API payload.
It checks that only user admins are added and that their image URL is
not an empty string. In doing this, also fixes an issue where the image
URL wouldn't be generated correctly.
## Discussion points
Some of the test feels like it might be better testing on a deeper level
(i.e. the account store). However, from an initial glance, I think that
would require more setup and work, so I'm leaving it in the dashboard
test for now as that's where it's ultimately useful. But we can discuss
if we should move it.
Ideally `feature_lifecycle_stage_entered{stage="archived"}` would allow
me to see how many flags are archived per week.
It seems like the numbers for this is a bit off, and wanted to extend
our current `feature_toggle_update` counter with action details.
Adds Unleash admins to the personal dashboard payload.
Uses the access store (and a new method) to fetch admins and maps it to
a new `MinimalUser` type. We already have a `User` class, but it
contains a lot of information we don't care about here, such as `isAPI`,
SCIM data etc.
In the UI, admins will be shown to users who are not part of any
projects. This is the default state for new viewer users, and can also
happen for editors if you archive the default project, for instance.
Tests in a follow-up PR
This PR adds all user-type owners of projects that you have access to to
the personal dashboard payload. It adds the new `projectOwners` property
regardless of whether you have access to any projects or not because it
required less code and fewer conditionals, but we can do the filtering
if we want to.
To add the owners, it uses the private project checker to get accessible
projects before passing those to the project owner read model, which has
a new method to fetch user owners for projects.
This trims role names before validation and subsequent validation.
This fixes a bug where you could have names that were empty or that
were duplicates of other names, but with leading or trailing
spaces. (They display the same in the UI).
This does not modify how we handle descriptions in the API. While the
UI form requires you to enter a description, the API does not. As
such, we can't make that required now without it being a breaking
change.
This change removes the flag used to anonymize project owners on the
way out. It was an issue in demo when we'd forgotten to configure the
email encryption. However, this issue has been resolved and we can
remove this check now.
This PR adds project owner information to the personal dashboard's
project payload.
To do so, it uses the existing project owners read model.
I've had to make a few changes to the project owners read model to
accomodate this:
- make the input type to `addOwners` more lenient. We only need the
project ids, so we can make that the only required property
- fall back to using email as the name if the user has no name or
username (such as if you sign up with the demo auth)
This PR adds some of the necessary project data to the personal
dashboard API: project names and ids, and the roles that the user has in
each of these projects.
I have not added project owners yet, as that would increase the
complexity a bit and I'd rather focus on that in a separate PR.
I have also not added projects you are part of through a group, though I
have added a placeholder test for that. I will address this in a
follow-up.
## About the changes
When trying to send messages longer than 3000 chars we get this error:
```
[ERROR] web-api:WebClient:0 failed to match all allowed schemas [json-pointer:/blocks/0/text]
[ERROR] web-api:WebClient:0 must be less than 3001 characters [json-pointer:/blocks/0/text/text]
[2024-09-23T10:10:15.676] [WARN] addon/slack-app - All (1) Slack client calls failed with the following errors: A platform error occurred: {"ok":false,"error":"invalid_blocks","errors":["failed to match all allowed schemas [json-pointer:/blocks/0/text]","must be less than 3001 characters [json-pointer:/blocks/0/text/text]"],"response_metadata":{"messages":["[ERROR] failed to match all allowed schemas [json-pointer:/blocks/0/text]","[ERROR] must be less than 3001 characters [json-pointer:/blocks/0/text/text]"],"scopes":["incoming-webhook","users:read","channels:read","groups:read","mpim:read","im:read","users:read.email","chat:write"],"acceptedScopes":["chat:write"]}}
```
This PR trims the text length to 3000 chars.
We also upgrade slack API due to some security fixes:
https://github.com/slackapi/node-slack-sdk/releases/tag/%40slack%2Fweb-api%407.3.4
After checking the migration guide to v7 it seems that none of the
breaking changes affect us:
https://github.com/slackapi/node-slack-sdk/wiki/Migration-Guide-for-web%E2%80%90api-v7
## Testing
I did manual test this integration and the fix. The way to reproduce is
adding a very long strategy name and sending that as an update on Slack:

Now the event succeeds and we notice on the integration event log that
the message was trimmed:

---------
Co-authored-by: Nuno Góis <github@nunogois.com>
https://linear.app/unleash/issue/2-2664/implement-event-tooltips
Implements event tooltips in the new event timeline.
This leverages our current `feature-event-formatter-md` to provide both
a label and a summary of the event. Whenever our new `eventTimeline`
flag is enabled, we enrich our events in our event search endpoint with
this information. We've discussed different options here and reached the
conclusion that this is the best path forward for now. This way we are
being consistent, DRY, relatively performant and it also gives us a
happy path forward if we decide to scope in the event log revamp, since
this data will already be present there.
We also added a new `label` property to each of our event types
currently in our event formatter. This way we can have a concise,
human-readable name for each event type, instead of exposing the
internal event type string.
~~We also fixed the way the event formatter handled bold text (as in,
**bold**). Before, it was wrapping them in *single asterisks*, but now
we're using **double asterisks**. We also abstracted this away into a
helper method aptly named `bold`. Of course, this change meant that a
bunch of snapshots and tests needed to be updated.~~
~~This new `bold` method also makes it super easy to revert this
decision if we choose to, for any reason. However I believe we should
stick with markdown formatting, since it is the most commonly supported
formatting syntax, so I see this as an important fix. It's also in the
name of the formatter (`md`). I also believe bold was the original
intent. If we want italic formatting we should implement it separately
at a later point.~~
Edit: It was _bold_ of me to assume this would work out of the box on
Slack. It does when you manually try it on the app, but not when using
the Slack client. See: https://github.com/Unleash/unleash/pull/8222


We now have customers that exceed INT capacity, so we need to change
this to BIGINT in client_metrics_env_variants_daily as well.
Even heavy users only have about 10000 rows here, so should be a quick
enough operation.
https://linear.app/unleash/issue/2-2658/create-eventtimeline-feature-flag
Adds a new `eventTimeline` feature flag for the new event timeline
feature.
I think `eventTimeline` is an appropriate name given the feature
description and the way it is evolving, but I'm open to suggestions.
~~This also assumes that this feature will target OSS.~~ Confirmed that
this will be a premium feature.
## Background
In #6380 we fixed a privilege escalation bug that allowed members of a
project that had permission to add users to the project with roles that
had a higher permission set than themselves. The PR linked essentially
constricts you only be able to assign users to roles that you possess
yourself if you are not an Admin or Project owner.
This fix broke expectations for another customer who needed to have a
project owner without the DELETE_PROJECT permission. The fix above made
it so that their custom project owner role only was able to assign users
to the project with the role that they posessed.
## Fix
Instead of looking directly at which role the role granter has, this PR
addresses the issue by making the assessment based on the permission
sets of the user and the roles to be granted. If the granter has all the
permissions of the role being granted, the granter is permitted to
assign the role.
## Other considerations
The endpoint to get roles was changed in this PR. It previously only
retrieved the roles that the user had in the project. This no-longer
makes sense because the user should be able to see other project roles
than the one they themselves hold when assigning users to the project.
The drawback of returning all project roles is that there may be a
project role in the list that the user does not have access to assign,
because they do not hold all the permissions required of the role. This
was discussed internally and we decided that it's an acceptable
trade-off for now because the complexities of returning a role list
based on comparing permissions set is not trivial. We would have to
retrieve each project role with permissions from the database, and run
the same in-memory check against the users permission to determine which
roles to return from this endpoint. Instead we opted for returning all
project roles and display an error if you try to assign a role that you
do not have access to.
## Follow up
When this is merged, there's no longer need for the frontend logic that
filters out roles in the role assignment form. I deliberately left this
out of the scope for this PR because I couldn't wrap my head around
everything that was going on there and I thought it was better to pair
on this with @chriswk or @nunogois in order to make sure we get this
right as the logic for this filtering seemed quite complex and was
touching multiple different components.
---------
Co-authored-by: Fredrik Strand Oseberg <fredrikstrandoseberg@Fredrik-sin-MacBook-Pro.local>
This appears to have been an oversight in the original implementation
of this endpoint. This seems to be the primary point of this
permission. Additionally, the docs mention that this permission should
allow you to do just that.
Note: I've not added any tests for this, because we don't typically add
tests for it. If we have an example to follow, I'd be very happy to add
it, though
https://github.com/Unleash/unleash/pull/7795 mistakenly included a
mention that these environment variables can be used:
- `UNLEASH_DEFAULT_ADMIN_NAME`
- `UNLEASH_DEFAULT_ADMIN_EMAIL`
However that's not really the case, since we decided to remove their
respective implementation before merging that PR.
https://linear.app/unleash/issue/2-2592/updateimprove-a-segment-via-api-call
Related to https://github.com/Unleash/unleash/issues/7987
This does not make the endpoint necessarily better - It's still a PUT
that acts as a PUT in some ways (expects specific required fields to be
present, resets the project to `null` if it's not included in the body)
and a PATCH in others (ignores most fields if they're not included in
the body). We need to have a more in-depth discussion about developing
long-term strategies for our API and respective OpenAPI spec.
However this at least includes the proper schema for the request body,
which is slightly better than before.
Clearing onboarding tables, because the data is invalid and we want to
start tracking all of this for only new customers.
This migration must be applied after the new logic is implemented.
We are observing incorrect data in Prometheus, which is consistently
non-reproducible. After a restart, the issue does not occur, but if the
pods run for an extended period, they seem to enter a strange state
where the counters become entangled and start sharing arbitrary values
that are added to the counters.
For example, the `feature_lifecycle_stage_entered` counter gets an
arbitrary value, such as 12, added when `inc()` is called. The
`exceedsLimitErrorCounter` shows the same behavior, and the code
implementation is identical.
We also tested some existing `increase()` counters, and they do not
suffer from this issue.
All calls to `counter.labels(labels).inc(`) will be replaced by
`counter.increment()` to try to mitigate the issue.
Previously we expected the tag to look like `type:value`. Now we allow
everything after first colon, as the value and not break query
`type:this:still:is:value`.
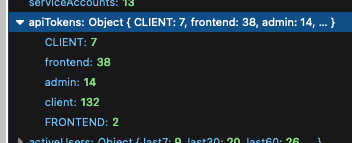
Fixes a bug where if you had API keys using different casing for the
same type, they'd come out as different types in the API token count
map. To get around it, we normalize the keys to lowercase before
inserting them into the map, taking into account any previous values
that might have existed for that type.
Should fix issues like this:
Updates the instance stats endpoint with
- maxEnvironmentStrategies
- maxConstraints
- maxConstraintValues
It adds the following rows to the front end table:
- segments (already in the payload, just not used for the table before)
- API tokens (separate rows for type, + one for total) (also existed
before, but wasn't listed)
- Highest number of strategies used for a single flag in a single
environment
- Highest number of constraints used on a single strategy
- Highest number of values used for a single constraint

Turns out we've been trying to return API token data in instance stats
for a while, but that the serialization has failed. Serializing a JS map
just yields an empty object.
This PR fixes that serialization and also adds API tokens to the
instance stats schema (it wasn't before, but we did return it). Adding
it to the schema is also part of making resource usage visible as part
of the soft limits project.
Path types in our openapi are inferred as string (which is a sensible
default). But we can be more specific and provide the right type for
each parameter. This is one example of how we can do that
{kind=link}