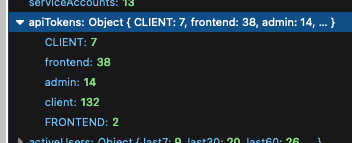
Fixes a bug where if you had API keys using different casing for the
same type, they'd come out as different types in the API token count
map. To get around it, we normalize the keys to lowercase before
inserting them into the map, taking into account any previous values
that might have existed for that type.
Should fix issues like this:
Updates the instance stats endpoint with
- maxEnvironmentStrategies
- maxConstraints
- maxConstraintValues
It adds the following rows to the front end table:
- segments (already in the payload, just not used for the table before)
- API tokens (separate rows for type, + one for total) (also existed
before, but wasn't listed)
- Highest number of strategies used for a single flag in a single
environment
- Highest number of constraints used on a single strategy
- Highest number of values used for a single constraint

Turns out we've been trying to return API token data in instance stats
for a while, but that the serialization has failed. Serializing a JS map
just yields an empty object.
This PR fixes that serialization and also adds API tokens to the
instance stats schema (it wasn't before, but we did return it). Adding
it to the schema is also part of making resource usage visible as part
of the soft limits project.
Path types in our openapi are inferred as string (which is a sensible
default). But we can be more specific and provide the right type for
each parameter. This is one example of how we can do that
This PR fixes an issue where the number of flags belonging to a project
was wrong in the new getProjectsForAdminUi.
The cause was that we now join with the events table to get the most
"lastUpdatedAt" data. This meant that we got multiple rows for each
flag, so we counted the same flag multiple times. The fix was to use a
"distinct".
Additionally, I used this as an excuse to write some more tests that I'd
been thinking about. And in doing so also uncovered another bug that
would only ever surface in verrry rare conditions: if a flag had been
created in project A, but moved to project B AND the
feature-project-change event hadn't fired correctly, project B's last
updated could show data from that feature in project A.
I've also taken the liberty of doing a little bit of cleanup.
## About the changes
When storing last seen metrics we no longer validate at insert time that
the feature exists. Instead, there's a job cleaning up on a regular
interval.
Metrics for features with more than 255 characters, makes the whole
batch to fail, resulting in metrics being lost.
This PR helps mitigate the issue while also logs long name feature names
Implements empty responses for the fake project read model. Instead of
throwing a not implemented error, we'll return empty results.
This makes some of the tests in enterprise pass.
This PR touches up a few small things in the project read model.
Fixes:
Use the right method name in the query/method timer for
`getProjectsForAdminUi`. I'd forgotten to change the timer name from the
original method name.
Spells the method name correctly for the `getMembersCount` timer (it
used to be `getMemberCount`, but the method is callled `getMembersCount`
with a plural s).
Changes:
Call the `getMembersCount` timer from within the `getMembersCount`
method itself. Instead of setting that timer up from two different
places, we can call it in the method we're timing. This wasn't a problem
previously, because the method was only called from a single place.
Assuming we always wanna time that query, it makes more sense to put the
timing in the actual method.
Hooks up the new project read model and updates the existing project
service to use it instead when the flag is on.
In doing:
- creates a composition root for the read model
- includes it in IUnleashStores
- updates some existing methods to accept either the old or the new
model
- updates the OpenAPI schema to deprecate the old properties
These are both related to the work on the project list improvements
project.
The `projectListImprovements` flag will be used to enable disable the
new project list improvements.
The `useProjectReadModel` flag will be used to enable/disable the use
of the new project read model and is mostly a safety feature.
Creates a new project read model exposing data to be used for the UI and
for the insights module.
The model contains two public methods, both based on the project store's
`getProjectsWithCounts`:
- `getProjectsForAdminUi`
- `getProjectsForInsights`
This mirrors the two places where the base query is actually in use
today and adapts the query to those two explicit cases.
The new `getProjectsForAdminUi` method also contains data for last flag
update and last flag metric reported, as required for the new projects
list screen.
Additionally the read model contains a private `getMembersCount` method,
which is also lifted from the project store. This method was only used
in the old `getProjectsWithCounts` method, so I have also removed the
method from the public interface.
This PR does *not* hook up the new read model to anything or delete any
existing uses of the old method.
## Why?
As mentioned in the background, this query is used in two places, both
to get data for the UI (directly or indirectly). This is consistent with
the principles laid out in our [ADR on read vs write
models](https://docs.getunleash.io/contributing/ADRs/back-end/write-model-vs-read-models).
There is an argument to be made, however, that the insights module uses
this as an **internal** read model, but the description of an internal
model ("Internal read models are typically narrowly focused on answering
one question and usually require simple queries compared to external
read models") does not apply here. It's closer to the description of
external read models: "View model will typically join data across a few
DB tables" for display in the UI.
## Discussion points
### What about properties on the schema that are now gone?
The `project-schema`, which is delivered to the UI through the
`getProjects` endpoint (and nowhere else, it seems), describes
properties that will no longer be sent to the front end, including
`defaultStickiness`, `avgTimeToProduction`, and more. Can we just stop
sending them or is that a breaking change?
The schema does not define them as required properties, so in theory,
not sending them isn't breaking any contracts. We can deprecate the
properties and just not populate them anymore.
At least that's my thought on it. I'm open to hearing other views.
### Can we add the properties in fewer lines of code?
Yes! The [first commit in this PR
(b7534bfa)](b7534bfa07)
adds the two new properties in 8 lines of code.
However, this comes at the cost of diluting the `getProjectsWithCounts`
method further by adding more properties that are not used by the
insights module. That said, that might be a worthwhile tradeoff.
## Background
_(More [details in internal slack
thread](https://unleash-internal.slack.com/archives/C046LV6HH6W/p1723716675436829))_
I noticed that the project store's `getProjectWithCounts` is used in
exactly two places:
1. In the project service method which maps directly to the project
controller (in both OSS and enterprise).
2. In the insights service in enterprise.
In the case of the controller, that’s the termination point. I’d guess
that when written, the store only served the purpose of showing data to
the UI.
In the event of the insights service, the data is mapped in
getProjectStats.
But I was a little surprised that they were sharing the same query, so I
decided to dig a little deeper to see what we’re actually using and what
we’re not (including the potential new columns). Here’s what I found.
Of the 14 already existing properties, insights use only 7 and the
project list UI uses only 10 (though the schema mentions all 14 (as far
as I could tell from scouring the code base)). Additionally, there’s two
properties that I couldn’t find any evidence of being used by either:
- default stickiness
- updatedAt (this is when the project was last updated; not its flags)
During adding privateProjectsChecker, I saw that events composition root
is not used almost at all.
Refactored code so we do not call new EventService anymore.
<!-- Thanks for creating a PR! To make it easier for reviewers and
everyone else to understand what your changes relate to, please add some
relevant content to the headings below. Feel free to ignore or delete
sections that you don't think are relevant. Thank you! ❤️ -->
## About the changes
When reading feature env strategies and there's no segments it returns
empty list of segments now. Previously it was undefined leading to
overly verbose change request diffs.
<img width="669" alt="Screenshot 2024-08-14 at 16 06 14"
src="https://github.com/user-attachments/assets/1ac6121b-1d6c-48c6-b4ce-3f26c53c6694">
### Important files
<!-- PRs can contain a lot of changes, but not all changes are equally
important. Where should a reviewer start looking to get an overview of
the changes? Are any files particularly important? -->
## Discussion points
<!-- Anything about the PR you'd like to discuss before it gets merged?
Got any questions or doubts? -->
https://linear.app/unleash/issue/2-2518/figure-out-how-to-create-the-initial-admin-user-in-unleash
The logic around `initAdminUser` that was introduced in
https://github.com/Unleash/unleash/pull/4927 confused me a bit. I wrote
new tests with what I assume are our expectations for this feature and
refactored the code accordingly, but would like someone to confirm that
it makes sense to them as well.
The logic was split into 2 different methods: one to get the initial
invite link, and another to send a welcome email. Now these two methods
are more granular than the previous alternative and can be used
independently of creating a new user.
---------
Co-authored-by: Gastón Fournier <gaston@getunleash.io>
For easy gitar integration, we need to have boolean in the event
payload.
We might rethink it when we add variants, but currently enabled with
variants is not used.
Changes the event search handling, so that searching by user uses the
user's ID, not the "createdBy" name in the event. This aligns better
with what the OpenAPI schema describes it.
After adding an index, the time for the new event search on 100k events
decreased from 5000ms to 4ms. This improvement is due to the query using
an index scan instead of a sequence scan.
Encountered this case after encrypting an already long email address.
This should mitigate the issue in demo instance. I don't think it's a
big issue to ignore the length when validating an email address cause
this is already limited at the DB layer by the column length
Adds an endpoint to return all event creators.
An interesting point is that it does not return the user object, but
just created_by as a string. This is because we do not store user IDs
for events, as they are not strictly bound to a user object, but rather
a historical user with the name X.
Previously people were able to send random data to feature type. Now it
is validated.
Fixes https://github.com/Unleash/unleash/issues/7751
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
Changed the url of event search to search/events to align with
search/features. With that created a search controller to keep all
searches under there.
Added first test.
This PR adds Grafana gauges for all the existing resource limits. The
primary purpose is to be able to use this in alerting. Secondarily, we
can also use it to get better insights into how many customers have
increased their limits, as well as how many people are approaching their
limit, regdardless of whether it's been increased or not.
## Discussion points
### Implementation
The first approach I took (in
87528b4c67),
was to add a new gauge for each resource limit. However, there's a lot
of boilerplate for it.
I thought doing it like this (the current implementation) would make it
easier. We should still be able to use the labelName to collate this in
Grafana, as far as I understand? As a bonus, we'd automatically get new
resource limits when we add them to the schema.
``` tsx
const resourceLimit = createGauge({
name: 'resource_limit',
help: 'The maximum number of resources allowed.',
labelNames: ['resource'],
});
// ...
for (const [resource, limit] of Object.entries(config.resourceLimits)) {
resourceLimit.labels({ resource }).set(limit);
}
```
That way, when checking the stats, we should be able to do something
like this:
``` promql
resource_limit{resource="constraintValues"}
```
### Do we need to reset gauges?
I noticed that we reset gauges before setting values in them all over
the place. I don't know if that's necessary. I'd like to get that double
clarified before merging this.
https://linear.app/unleash/issue/2-2501/adapt-origin-middleware-to-stop-logging-ui-requests-and-start
This adapts the new origin middleware to stop logging UI requests (too
noisy) and adds new Prometheus metrics.
<img width="745" alt="image"
src="https://github.com/user-attachments/assets/d0c7f51d-feb6-4ff5-b856-77661be3b5a9">
This should allow us to better analyze this data. If we see a lot of API
requests, we can dive into the logs for that instance and check the
logged data, like the user agent.
This PR adds some helper methods to make listening and emitting metric
events more strict in terms of types. I think it's a positive change
aligned with our scouting principle, but if you think it's complex and
does not belong here I'm happy with dropping it.
Add ability to format format event as Markdown in generic webhooks,
similar to Datadog integration.
Closes https://github.com/Unleash/unleash/issues/7646
Co-authored-by: Nuno Góis <github@nunogois.com>
https://linear.app/unleash/issue/2-2469/keep-the-latest-event-for-each-integration-configuration
This makes it so we keep the latest event for each integration
configuration, along with the previous logic of keeping the latest 100
events of the last 2 hours.
This should be a cheap nice-to-have, since now we can always know what
the latest integration event looked like for each integration
configuration. This will tie-in nicely with the next task of making the
latest integration event state visible in the integration card.
Also improved the clarity of the auto-deletion explanation in the modal.
This PR adds the UI part of feature flag collaborators. Collaborators are hidden on windows smaller than size XL because we're not sure how to deal with them in those cases yet.
https://linear.app/unleash/issue/2-2439/create-new-integration-events-endpointhttps://linear.app/unleash/issue/2-2436/create-new-integration-event-openapi-schemas
This adds a new `/events` endpoint to the Addons API, allowing us to
fetch integration events for a specific integration configuration id.
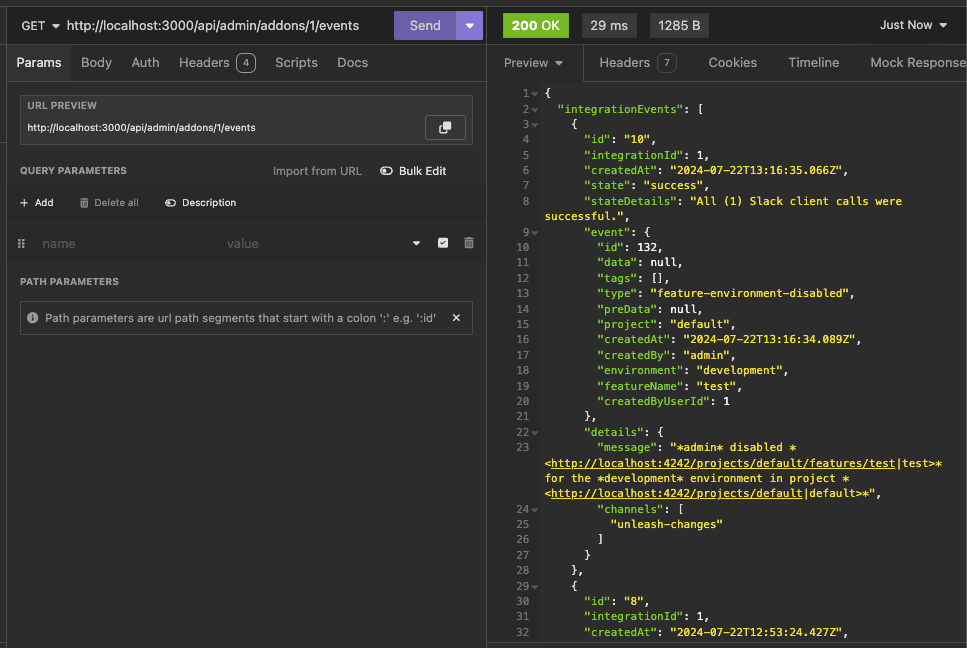
Also includes:
- `IntegrationEventsSchema`: New schema to represent the response object
of the list of integration events;
- `yarn schema:update`: New `package.json` script to update the OpenAPI
spec file;
- `BasePaginationParameters`: This is copied from Enterprise. After
merging this we should be able to refactor Enterprise to use this one
instead of the one it has, so we don't repeat ourselves;
We're also now correctly representing the BIGSERIAL as BigInt (string +
pattern) in our OpenAPI schema. Otherwise our validation would complain,
since we're saying it's a number in the schema but in fact returning a
string.
This PR allows you to gradually lower constraint values, even if they're
above the limits.
It does, however, come with a few caveats because of how Unleash deals
with constraints:
Constraints are just json blobs. They have no IDs or other
distinguishing features. Because of this, we can't compare the current
and previous state of a specific constraint.
What we can do instead, is to allow you to lower the amount of
constraint values if and only if the number of constraints hasn't
changed. In this case, we assume that you also haven't reordered the
constraints (not possible from the UI today). That way, we can compare
constraint values between updated and existing constraints based on
their index in the constraint list.
It's not foolproof, but it's a workaround that you can use. There's a
few edge cases that pop up, but that I don't think it's worth trying to
cover:
Case: If you **both** have too many constraints **and** too many
constraint values
Result: You won't be allowed to lower the amount of constraints as long
as the amount of strategy values is still above the limit.
Workaround: First, lower the amount of constraint values until you're
under the limit and then lower constraints. OR, set the constraint you
want to delete to a constraint that is trivially true (e.g. `currentTime
> yesterday` ). That will essentially take that constraint out of the
equation, achieving the same end result.
Case: You re-order constraints and at least one of them has too many
values
Result: You won't be allowed to (except for in the edge case where the
one with too many values doesn't move or switches places with another
one with the exact same amount of values).
Workaround: We don't need one. The order of constraints has no effect on
the evaluation.
https://linear.app/unleash/issue/2-2450/register-integration-events-webhook
Registers integration events in the **Webhook** integration.
Even though this touches a lot of files, most of it is preparation for
the next steps. The only actual implementation of registering
integration events is in the **Webhook** integration. The rest will
follow on separate PRs.
Here's an example of how this looks like in the database table:
```json
{
"id": 7,
"integration_id": 2,
"created_at": "2024-07-18T18:11:11.376348+01:00",
"state": "failed",
"state_details": "Webhook request failed with status code: ECONNREFUSED",
"event": {
"id": 130,
"data": null,
"tags": [],
"type": "feature-environment-enabled",
"preData": null,
"project": "default",
"createdAt": "2024-07-18T17:11:10.821Z",
"createdBy": "admin",
"environment": "development",
"featureName": "test",
"createdByUserId": 1
},
"details": {
"url": "http://localhost:1337",
"body": "{ \"id\": 130, \"type\": \"feature-environment-enabled\", \"createdBy\": \"admin\", \"createdAt\": \"2024-07-18T17: 11: 10.821Z\", \"createdByUserId\": 1, \"data\": null, \"preData\": null, \"tags\": [], \"featureName\": \"test\", \"project\": \"default\", \"environment\": \"development\" }"
}
}
```
This PR updates the limit validation for constraint numbers on a single
strategy. In cases where you're already above the limit, it allows you
to still update the strategy as long as you don't add any **new**
constraints (that is: the number of constraints doesn't increase).
A discussion point: I've only tested this with unit tests of the method
directly. I haven't tested that the right parameters are passed in from
calling functions. The main reason being that that would involve
updating the fake strategy and feature stores to sync their flag lists
(or just checking that the thrown error isn't a limit exceeded error),
because right now the fake strategy store throws an error when it
doesn't find the flag I want to update.
https://linear.app/unleash/issue/2-2453/validate-patched-data-against-schema
This adds schema validation to patched data, fixing potential issues of
patching data to an invalid state.
This can be easily reproduced by patching a strategy constraints to be
an object (invalid), instead of an array (valid):
```sh
curl -X 'PATCH' \
'http://localhost:4242/api/admin/projects/default/features/test/environments/development/strategies/8cb3fec6-c40a-45f7-8be0-138c5aaa5263' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '[
{
"path": "/constraints",
"op": "replace",
"from": "/constraints",
"value": {}
}
]'
```
Unleash will accept this because there's no validation that the patched
data actually looks like a proper strategy, and we'll start seeing
Unleash errors due to the invalid state.
This PR adapts some of our existing logic in the way we handle
validation errors to support any dynamic object. This way we can perform
schema validation with any object and still get the benefits of our
existing validation error handling.
This PR also takes the liberty to expose the full instancePath as
propertyName, instead of only the path's last section. We believe this
has more upsides than downsides, especially now that we support the
validation of any type of object.

This PR adds prometheus metrics for when users attempt to exceed the
limits for a given resource.
The implementation sets up a second function exported from the
ExceedsLimitError file that records metrics and then throws the error.
This could also be a static method on the class, but I'm not sure that'd
be better.
This PR updates the OpenAPI error converter to also work for errors with
query parameters.
We previously only sent the body of the request along with the error,
which meant that query parameter errors would show up incorrectly.
For instance given a query param with the date format and the invalid
value `01-2020-01`, you'd previously get the message:
> The `from` value must match format "date". You sent undefined
With this change, you'll get this instead:
> The `from` value must match format "date". You sent "01-2020-01".
The important changes here are two things:
- passing both request body and query params
- the 3 lines in `fromOpenApiValidationError` that check where we should
get the value you sent from.
The rest of it is primarily updating tests to send the right arguments
and some slight rewording to more accurately reflect that this can be
either request body or query params.
https://linear.app/unleash/issue/2-2435/create-migration-for-a-new-integration-events-table
Adds a DB migration that creates the `integration_events` table:
- `id`: Auto-incrementing primary key;
- `integration_id`: The id of the respective integration (i.e.
integration configuration);
- `created_at`: Date of insertion;
- `state`: Integration event state, as text. Can be anything we'd like,
but I'm thinking this will be something like:
- Success ✅
- Failed ❌
- SuccessWithErrors ⚠️
- `state_details`: Expands on the previous column with more details, as
text. Examples:
- OK. Status code: 200
- Status code: 429 - Rate limit reached
- No access token provided
- `event`: The whole event object, stored as a JSON blob;
- `details`: JSON blob with details about the integration execution.
Will depend on the integration itself, but for example:
- Webhook: Request body
- Slack App: Message text and an array with all the channels we're
posting to
I think this gives us enough flexibility to cover all present and
(possibly) future integrations, but I'd like to hear your thoughts.
I'm also really torn on what to call this table:
- `integration_events`: Consistent with the feature name. Addons are now
called integrations, so this would be consistent with the new thing;
- `addon_events`: Consistent with the existing `addons` table.
Our CSP reports that unsafe-inline is not recommended for styleSrc. This
PR adds a flag for making it possible to remove this element of our CSP
headers. It should allow us to see what (if anything) breaks hard.
We'll store hashes for the last 5 passwords, fetch them all for the user
wanting to change their password, and make sure the password does not
verify against any of the 5 stored hashes.
Includes some password-related UI/UX improvements and refactors. Also
some fixes related to reset password rate limiting (instead of an
unhandled exception), and token expiration on error.
---------
Co-authored-by: Nuno Góis <github@nunogois.com>
PR #7519 introduced the pattern of using `createApiTokenService` instead
of newing it up. This usage was introduced in a concurrent PR (#7503),
so we're just cleaning up and making the usage consistent.
Deletes API tokens bound to specific projects when the last project they're mapped to is deleted.
---------
Co-authored-by: Tymoteusz Czech <2625371+Tymek@users.noreply.github.com>
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
If you have SDK tokens scoped to projects that are deleted, you should
not get access to any flags with those.
---------
Co-authored-by: David Leek <david@getunleash.io>
This PR adds a feature flag limit to Unleash. It's set up to be
overridden in Enterprise, where we turn the limit up.
I've also fixed a couple bugs in the fake feature flag store.
This adds an extended metrics format to the metrics ingested by Unleash
and sent by running SDKs in the wild. Notably, we don't store this
information anywhere new in this PR, this is just streamed out to
Victoria metrics - the point of this project is insight, not analysis.
Two things to look out for in this PR:
- I've chosen to take extend the registration event and also send that
when we receive metrics. This means that the new data is received on
startup and on heartbeat. This takes us in the direction of collapsing
these two calls into one at a later point
- I've wrapped the existing metrics events in some "type safety", it
ain't much because we have 0 type safety on the event emitter so this
also has some if checks that look funny in TS that actually check if the
data shape is correct. Existing tests that check this are more or less
preserved
This PR adds the back end for API token resource limits.
It adds the limit to the schema and checks the limit in the service.
## Discussion points
The PAT service uses a different service and different store entirely,
so I have not included testing any edge cases where PATs are included.
However, that could be seen as "knowing too much". We could add tests
that check both of the stores in tandem, but I think it's overkill for
now.
This PR updates the Unleash UI to use the new environment limit.
As it turns out, we already had an environment limit in the UI, but it
was hardcoded (luckily, its value is the same as the new default value
🥳).
In addition to the existing places this limit was used, it also disables
the "new environment" button if you've reached the limit. Because this
limit already exists, I don't think we need a flag for it. The only
change is that you can't click a button (that should be a link!) that
takes you to a page you can't do anything on.
This PR adds limits for environments to the resource limit schema. The
actual limiting will have to be done in Enterprise, however, so this is
just laying the groundwork.
This fixes the issue where project names that are 100 characters long
or longer would cause the project creation to fail. This is because
the resulting ID would be longer than the 100 character limit imposed
by the back end.
We solve this by capping the project ID to 90 characters, which leaves
us with 10 characters for the suffix, meaning you can have 1 billion
projects (999,999,999 + 1) that start with the same 90
characters (after slugification) before anything breaks.
It's a little shorter than what it strictly has to be (we could
probably get around with 95 characters), but at this point, you're
reaching into edge case territory anyway, and I'd rather have a little
too much wiggle room here.
{kind=link}