In this PR I integrate the Unleash React SDK with the Admin UI.
We also take advantage of Unleash Hosted Edge behind the scenes with
multiple regions to get the evaluations close to the end user.
This is exposing information we already have about permissions in a UI
that should help users have an overview of the permissions of a user
with regards to projects and environments
This test was flaky once an hour because subminutes 3 made it fall into
the wrong bucket when tests were run exactly or minutes after the our
had passed.
Also, the databases created were created with the system clock. I
altered it to be explicitly UTC.
## About the changes
SCIM provisioned users ended up without a root role. Unleash was
assigning them the Viewer role by code but some queries using the db to
resolve the role did not have the same logic leading to weird behaviors.
This amends the situation by assigning the Viewer role to those users
following the least privilege principle.
Also adds a warning when assuming the Viewer role. That should never
happen but we want to be confident before removing it.
Depends on
https://github.com/bricks-software/unleash-enterprise/pull/164
As part of preparation for ESM and node/TSC updates, this PR will make
Unleash build with strictNullChecks set to true, since that's what's in
our tsconfig file. Hence, this PR also removes the `--strictNullChecks
false` flag in our compile tasks in package.json.
TL;DR - Clean up your code rather than turning off compiler security
features :)
Changes to migration file -
20220603081324-add-archive-at-to-feature-toggle.js
1. Fixes the migration script where features table is updated with
archived_at column with the latest date instead of taking the date from
the events table.
2. Also it fails for the latest toggle which was archived and then
revived but after migration it updates the toggle as archived toggle.
3. Also because of the buggy reference to the outer join's events table
`e` its taking a huge time to run the migration.
This PR fixes all the above issues.
## About the changes
We have faced an issue during migration of unleash-server from 4.8.2 to
6.6.0 where one of our toggle which was archived and unarchived once
before migration and that was the latest toggle in terms of the archived
date, but after the migration was ran it was in archived status.
Upon further debugging and running the SQL command in the features table
migration file we noticed that we should not be referencing the outer
join's events table `e` for the feature_name check and additionally we
should add the features table's archived toggle check instead.
### Important files
The change in only in this file.
[20220603081324-add-archive-at-to-feature-toggle.js](https://github.com/Unleash/unleash/pull/9518/files#diff-b91c299b96edc46ca3a1963bf54966aa777c9fa107f3bd8b45f5fb54dc57460e)
## Discussion points
Let me know if any further details is required.
## About the changes
Some automation may keep some data up-to-date (e.g. segments). These
updates sometimes don't generate changes but we're still storing these
events in the event log and triggering reactions to those events.
Arguably, this could be done in each service domain logic, but it seems
to be a pretty straightforward solution: if preData and data are
provided, it means some change happened. Other events that don't have
preData or don't have data are treated as before.
Tests were added to validate we don't break other events.
When project is moved, then Unleash creates only one event, which is for
target project.
We also need one for source project, to know that project was moved out
of it.
Test will be in enterprise repo.
This fixes a problem where the yggdrasil-engine does not send the
correct value for bucket.start. In practice clients sends metrics every
60s and it does not matter if we use start or the stop timestamp to
resolve the nearest full hour.
Currently, in enterprise we're struggling with setting service and
transactionality; all our verfications says that the setting key is not
present, so setting-store happily tries to insert a new row with a new
PK. However, somehow at the same time, the key already exists. This
commit adds conflict handling to the insertNewRow.
Fixes the height discrepancy between add strategy and more strategies
buttons, both with and without the flag enabled.
The essence of the fix is to make the "more strategies" button's height
dynamic and grow to match the height of the other button.
Before (flag enabled):

After (flag enabled):

Before (flag disabled):

After (flag disabled):
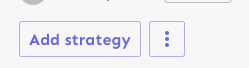
As a bonus: also enables the ui font redesign flag for server-dev.
If you're very sharp-eyed, you might notice a few things:
1. There's more padding on the new button. This was done in concert with
UX when we noticed there was more padding on other buttons. So as a
result, we set the button type to the default instead of "small".
1. The kebab button isn't perfectly square with the flag on. There's a
few issues here, but essentially: to use `aspect-ratio: 1`, you need
either a height or a width set. Because we want everything here to be
auto-generated (use the button's intrinsic height), I couldn't make it
work. In the end, I think this is close enough. If you have other ideas,
you're very welcome to try and fix it.
## About the changes
Based on the first hypothesis from
https://github.com/Unleash/unleash/pull/9264, I decided to find an
alternative way of initializing the DB, mainly trying to run migrations
only once and removing that from the actual test run.
I found in [Postgres template
databases](https://www.postgresql.org/docs/current/manage-ag-templatedbs.html)
an interesting option in combination with jest global initializer.
### Changes on how we use DBs for testing
Previously, we were relying on a single DB with multiple schemas to
isolate tests, but each schema was empty and required migrations or
custom DB initialization scripts.
With this method, we don't need to use different schema names
(apparently there's no templating for schemas), and we can use new
databases. We can also eliminate custom initialization code.
### Legacy tests
This method also highlighted some wrong assumptions in existing tests.
One example is the existence of `default` environment, that because of
being deprecated is no longer available, but because tests are creating
the expected db state manually, they were not updated to match the
existing db state.
To keep tests running green, I've added a configuration to use the
`legacy` test setup (24 tests). By migrating these, we'll speed up
tests, but the code of these tests has to be modified, so I leave this
for another PR.
## Downsides
1. The template db initialization happens at the beginning of any test,
so local development may suffer from slower unit tests. As a workaround
we could define an environment variable to disable the db migration
2. Proliferation of test dbs. In ephemeral environments, this is not a
problem, but for local development we should clean up from time to time.
There's the possibility of cleaning up test dbs using the db name as a
pattern:
2ed2e1c274/scripts/jest-setup.ts (L13-L18)
but I didn't want to add this code yet. Opinions?
## Benefits
1. It allows us migrate only once and still get the benefits of having a
well known state for tests.
3. It removes some of the custom setup for tests (which in some cases
ends up testing something not realistic)
4. It removes the need of testing migrations:
https://github.com/Unleash/unleash/blob/main/src/test/e2e/migrator.e2e.test.ts
as migrations are run at the start
5. Forces us to keep old tests up to date when we modify our database
Adds a killswitch called "filterExistingFlagNames". When enabled it will
filter out reported SDK metrics and remove all reported metrics for
names that does not match an exiting feature flag in Unleash.
This have proven critical in the rare case of an SDK that start sending
random flag-names back to unleash, and thus filling up the database. At
some point the database will start slowing down due to the noisy data.
In order to not resolve the flagNames all the time we have added a small
cache (10s) for feature flag names. This gives a small delay (10s) from
flag is created until we start allow metrics for the flag when
kill-switch is enabled. We should probably listen to the event-stream
and use that invalidate the cache when a flag is created.
## About the changes
Validations in the constructor were executed on the way out (i.e. when
reading users). Instead we should validate when we insert the users.
We're also relaxing the email validation to support top domain emails
(e.g. `...@jp`)
This is implementing the segments events for delta API. Previous version
of delta API, we were just sending all of the segments. Now we will have
`segment-updated` and `segment-removed `events coming to SDK.
This PR sets up the application to accept a value from a variant we
control to set the font size of the application on a global level. If it
fails, the value falls back to the previously set CSS value.
Add new methods to the store behind data usage metrics that accept date
ranges instead of a single month. The old data collection methods
re-route to the new ones instead, so the new methods are tested
implicitly.
Also deprecates the new endpoint that's not in use anywhere except in an
unused service method in Enterprise yet.
## Discussion point:
Accepts from and to params as dates for type safety. You can send unparseable strings, but if you send a date object, you know it'll work.
Leaves the use of the old method in `src/lib/features/instance-stats/instance-stats-service.ts` to keep changes small.
We are changing how the Delta API works, as discussed:
1. We have removed the `updated` and `removed` arrays and now keep
everything in the `events` array.
2. We decided to keep the hydration cache separate from the events array
internally. Since the hydration cache has a special structure and may
contain not just one feature but potentially 1,000 features, it behaved
differently, requiring a lot of special logic to handle it.
3. Implemented `nameprefix` filtering, which we were missing before.
Things still to implement:
1. Segment hydration and updates to it.
Add support for querying the traffic data usage store for the aggregated data for an arbitrary number of months back.
Adds a new `getTrafficDataForMonthRange(monthsBack: number)` method to the store that aggregates data on a monthly basis by status code and traffic group. Returns a new type with month data instead of day data.
This PR implements a first version of the new month/range picker for the
data usage graphs. It's minimally hooked up to the existing
functionality to not take anything away.
This primary purpose of this PR is to get the design and interaction out
on sandbox so that UX can have a look and we can make adjustments.
As such, there are a few things in the code that we'll want to clean up
before removing the flag later:
- for faster iteration, I've used a lot of CSS nesting and element
selectors. this isn't usually how we do it here, so we'll probably want
to extract into styled components later
- there is a temporary override of the value in the period selector so
that you can select ranges. It won't affect the chart state, but it
affects the selector state. Again, this lets you see how it acts and
works.
- I've added a `NewHeader` component because the existing setup smushed
the selector (it's a MUI grid setup, which isn't very flexible). I don't
know what we want to do with this in the end, but the existing chart
*does* have some problems when you resize your window, at least
(although this is likely due to the chart, and can be solved in the same
way that we did for the personal dashboards).

Currently, every time you archived feature, it created
feature-dependencies-removed event.
This PR adds a check to only create events for those features that have
dependency.
We got an event for a scheduled application success today that looked a
little something like this:
> Successfully applied the scheduled change request #1168 in the
production environment in project eg by gaston in project eg.
Notice that we're stating the project twice (once with a link (removed
here) and once without).
This PR removes the redundancy in CR events:
The project is already included in the `changeRequest` variable, which
is populated in `src/lib/addons/feature-event-formatter-md.ts` by
the `generateChangeRequestLink` function.
The (current) definition is:
```typescript
generateChangeRequestLink(event: IEvent): string | undefined {
const { preData, data, project, environment } = event;
const changeRequestId =
data?.changeRequestId || preData?.changeRequestId;
if (project && changeRequestId) {
const url = `${this.unleashUrl}/projects/${project}/change-requests/${changeRequestId}`;
const text = `#${changeRequestId}`;
const featureLink = this.generateFeatureLink(event);
const featureText = featureLink
? ` for feature flag ${this.bold(featureLink)}`
: '';
const environmentText = environment
? ` in the ${this.bold(environment)} environment`
: '';
const projectLink = this.generateProjectLink(event);
const projectText = project
? ` in project ${this.bold(projectLink)}`
: '';
if (this.linkStyle === LinkStyle.SLACK) {
return `${this.bold(`<${url}|${text}>`)}${featureText}${environmentText}${projectText}`;
} else {
return `${this.bold(`[${text}](${url})`)}${featureText}${environmentText}${projectText}`;
}
}
}
```
Which includes links, env, and project info already.
Weird thing is that I could not reproduce it locally, but I have a
theory to fix our delta mismatch.
Revisions are added to the delta every second.
This means that in a single revision, you can disable an event, remove a
dependency, and archive it simultaneously. These actions are usually
performed together since archiving an event will inherently disable it,
remove its dependencies, and so on.
Currently, we observe these events happening within the same revision.
However, since we were checking `.updated` last, the event was always
removed from the `removedMap`.
Now, by checking `.removed` last, the archive action will properly
propagate to the revision.
Our delta API was returning archived feature as updated. Now making sure
we do not put `archived-feature `event into `updated` event array.
Also stop returning removed as complex object.
## About the changes
Moved Open API validation handler to the controller layer to reuse on
all services such as project and segments, and also removed unnecessary
middleware at the top level, `app.ts`, and method, `useErrorHandler` in
`openapi-service.ts`.
### Important files
#### Before
<img width="1510" alt="1 Before"
src="https://github.com/user-attachments/assets/96ac245d-92ac-469e-a097-c6c0b78d0def">
Express cant' parse the path parameter because it doesn't be specified
on the `use` method. Therefore, it returns `undefined` as an error
message.
#### After
<img width="1510" alt="2 After"
src="https://github.com/user-attachments/assets/501dae6c-fef5-4e77-94c3-128a9f7210da">
Express can parse the path parameter because I change to specify it on
the controller layer. Accordingly, it returns `test`.
Trying again, now with a tested function for resolvingIsOss.
Still want to test this on a pro instance in sandbox before we deploy
this to our customers to avoid what happened Friday.
---------
Co-authored-by: Gastón Fournier <gaston@getunleash.io>
When there is new revision, we will start storing memory footprint for
old client-api and the new delta-api.
We will be sending it as prometheus metrics.
The memory size will only be recalculated if revision changes, which
does not happen very often.
## About the changes
According to some logs, sdks can be undefined:
```
TypeError: Cannot read properties of null (reading 'sort')\n at /unleash/node_modules/unleash-server/dist/lib/db/client-applications-store.js:330:22\n
```
This is still raw and experimental.
We started to pull deleted features from event payload.
Now we put full query towards read model.
Co-Author: @FredrikOseberg
This PR refactors the method that listens on revision changes:
- Now supports all environments
- Removed unnecessary populate cache method
# Discussion point
In the listen method, should we implement logic to look into which
environments the events touched? By doing this we would:
- Reduce cache size
- Save some memory/CPU if the environment is not initialized in the
cache, because we could skip the DB calls.
This is based on the exising client feature toggle store, but some
alterations.
1. We support all of the querying it did before.
2. Added support to filter by **featureNames**
3. Simplified logic, so we do not have admin API logic
- no return of tags
- no return of last seen
- no return of favorites
- no playground logic
Next PR will try to include the revision ID.
This is not changing existing logic.
We are creating a new endpoint, which is guarded behind a flag.
---------
Co-authored-by: Simon Hornby <liquidwicked64@gmail.com>
Co-authored-by: FredrikOseberg <fredrik.no@gmail.com>
Added more tests around specific plans. Also added snapshot as per our
conversation @gastonfournier, but I'm unsure how much value it will give
because it seems that the tests should already catch this using
respondWithValidation and the OpenAPI schema. The problem here is that
empty array is a valid state, so there were no reason for the schema to
break the tests.
From 13 seconds to 0.1 seconds.
1. Joining 1 million events to projects/features is slow. **Solved by
using CTE.**
2. Running grouping on 1 million rows is slow. **Solved by adding
index.**
{kind=link}