Adds an endpoint to return all event creators.
An interesting point is that it does not return the user object, but
just created_by as a string. This is because we do not store user IDs
for events, as they are not strictly bound to a user object, but rather
a historical user with the name X.
Previously people were able to send random data to feature type. Now it
is validated.
Fixes https://github.com/Unleash/unleash/issues/7751
---------
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
Changed the url of event search to search/events to align with
search/features. With that created a search controller to keep all
searches under there.
Added first test.
https://linear.app/unleash/issue/2-2469/keep-the-latest-event-for-each-integration-configuration
This makes it so we keep the latest event for each integration
configuration, along with the previous logic of keeping the latest 100
events of the last 2 hours.
This should be a cheap nice-to-have, since now we can always know what
the latest integration event looked like for each integration
configuration. This will tie-in nicely with the next task of making the
latest integration event state visible in the integration card.
Also improved the clarity of the auto-deletion explanation in the modal.
https://linear.app/unleash/issue/2-2439/create-new-integration-events-endpointhttps://linear.app/unleash/issue/2-2436/create-new-integration-event-openapi-schemas
This adds a new `/events` endpoint to the Addons API, allowing us to
fetch integration events for a specific integration configuration id.
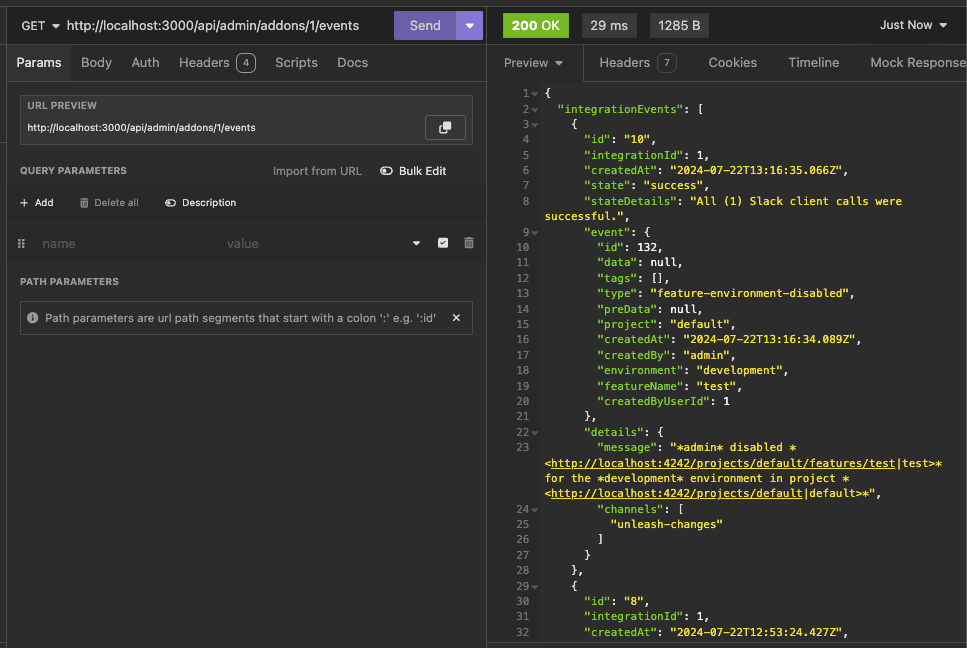
Also includes:
- `IntegrationEventsSchema`: New schema to represent the response object
of the list of integration events;
- `yarn schema:update`: New `package.json` script to update the OpenAPI
spec file;
- `BasePaginationParameters`: This is copied from Enterprise. After
merging this we should be able to refactor Enterprise to use this one
instead of the one it has, so we don't repeat ourselves;
We're also now correctly representing the BIGSERIAL as BigInt (string +
pattern) in our OpenAPI schema. Otherwise our validation would complain,
since we're saying it's a number in the schema but in fact returning a
string.
This PR allows you to gradually lower constraint values, even if they're
above the limits.
It does, however, come with a few caveats because of how Unleash deals
with constraints:
Constraints are just json blobs. They have no IDs or other
distinguishing features. Because of this, we can't compare the current
and previous state of a specific constraint.
What we can do instead, is to allow you to lower the amount of
constraint values if and only if the number of constraints hasn't
changed. In this case, we assume that you also haven't reordered the
constraints (not possible from the UI today). That way, we can compare
constraint values between updated and existing constraints based on
their index in the constraint list.
It's not foolproof, but it's a workaround that you can use. There's a
few edge cases that pop up, but that I don't think it's worth trying to
cover:
Case: If you **both** have too many constraints **and** too many
constraint values
Result: You won't be allowed to lower the amount of constraints as long
as the amount of strategy values is still above the limit.
Workaround: First, lower the amount of constraint values until you're
under the limit and then lower constraints. OR, set the constraint you
want to delete to a constraint that is trivially true (e.g. `currentTime
> yesterday` ). That will essentially take that constraint out of the
equation, achieving the same end result.
Case: You re-order constraints and at least one of them has too many
values
Result: You won't be allowed to (except for in the edge case where the
one with too many values doesn't move or switches places with another
one with the exact same amount of values).
Workaround: We don't need one. The order of constraints has no effect on
the evaluation.
https://linear.app/unleash/issue/2-2450/register-integration-events-webhook
Registers integration events in the **Webhook** integration.
Even though this touches a lot of files, most of it is preparation for
the next steps. The only actual implementation of registering
integration events is in the **Webhook** integration. The rest will
follow on separate PRs.
Here's an example of how this looks like in the database table:
```json
{
"id": 7,
"integration_id": 2,
"created_at": "2024-07-18T18:11:11.376348+01:00",
"state": "failed",
"state_details": "Webhook request failed with status code: ECONNREFUSED",
"event": {
"id": 130,
"data": null,
"tags": [],
"type": "feature-environment-enabled",
"preData": null,
"project": "default",
"createdAt": "2024-07-18T17:11:10.821Z",
"createdBy": "admin",
"environment": "development",
"featureName": "test",
"createdByUserId": 1
},
"details": {
"url": "http://localhost:1337",
"body": "{ \"id\": 130, \"type\": \"feature-environment-enabled\", \"createdBy\": \"admin\", \"createdAt\": \"2024-07-18T17: 11: 10.821Z\", \"createdByUserId\": 1, \"data\": null, \"preData\": null, \"tags\": [], \"featureName\": \"test\", \"project\": \"default\", \"environment\": \"development\" }"
}
}
```
This PR updates the limit validation for constraint numbers on a single
strategy. In cases where you're already above the limit, it allows you
to still update the strategy as long as you don't add any **new**
constraints (that is: the number of constraints doesn't increase).
A discussion point: I've only tested this with unit tests of the method
directly. I haven't tested that the right parameters are passed in from
calling functions. The main reason being that that would involve
updating the fake strategy and feature stores to sync their flag lists
(or just checking that the thrown error isn't a limit exceeded error),
because right now the fake strategy store throws an error when it
doesn't find the flag I want to update.
https://linear.app/unleash/issue/2-2453/validate-patched-data-against-schema
This adds schema validation to patched data, fixing potential issues of
patching data to an invalid state.
This can be easily reproduced by patching a strategy constraints to be
an object (invalid), instead of an array (valid):
```sh
curl -X 'PATCH' \
'http://localhost:4242/api/admin/projects/default/features/test/environments/development/strategies/8cb3fec6-c40a-45f7-8be0-138c5aaa5263' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '[
{
"path": "/constraints",
"op": "replace",
"from": "/constraints",
"value": {}
}
]'
```
Unleash will accept this because there's no validation that the patched
data actually looks like a proper strategy, and we'll start seeing
Unleash errors due to the invalid state.
This PR adapts some of our existing logic in the way we handle
validation errors to support any dynamic object. This way we can perform
schema validation with any object and still get the benefits of our
existing validation error handling.
This PR also takes the liberty to expose the full instancePath as
propertyName, instead of only the path's last section. We believe this
has more upsides than downsides, especially now that we support the
validation of any type of object.

This PR adds prometheus metrics for when users attempt to exceed the
limits for a given resource.
The implementation sets up a second function exported from the
ExceedsLimitError file that records metrics and then throws the error.
This could also be a static method on the class, but I'm not sure that'd
be better.
PR #7519 introduced the pattern of using `createApiTokenService` instead
of newing it up. This usage was introduced in a concurrent PR (#7503),
so we're just cleaning up and making the usage consistent.
Deletes API tokens bound to specific projects when the last project they're mapped to is deleted.
---------
Co-authored-by: Tymoteusz Czech <2625371+Tymek@users.noreply.github.com>
Co-authored-by: Thomas Heartman <thomas@getunleash.io>
If you have SDK tokens scoped to projects that are deleted, you should
not get access to any flags with those.
---------
Co-authored-by: David Leek <david@getunleash.io>
This PR adds a feature flag limit to Unleash. It's set up to be
overridden in Enterprise, where we turn the limit up.
I've also fixed a couple bugs in the fake feature flag store.
This adds an extended metrics format to the metrics ingested by Unleash
and sent by running SDKs in the wild. Notably, we don't store this
information anywhere new in this PR, this is just streamed out to
Victoria metrics - the point of this project is insight, not analysis.
Two things to look out for in this PR:
- I've chosen to take extend the registration event and also send that
when we receive metrics. This means that the new data is received on
startup and on heartbeat. This takes us in the direction of collapsing
these two calls into one at a later point
- I've wrapped the existing metrics events in some "type safety", it
ain't much because we have 0 type safety on the event emitter so this
also has some if checks that look funny in TS that actually check if the
data shape is correct. Existing tests that check this are more or less
preserved
This fixes the issue where project names that are 100 characters long
or longer would cause the project creation to fail. This is because
the resulting ID would be longer than the 100 character limit imposed
by the back end.
We solve this by capping the project ID to 90 characters, which leaves
us with 10 characters for the suffix, meaning you can have 1 billion
projects (999,999,999 + 1) that start with the same 90
characters (after slugification) before anything breaks.
It's a little shorter than what it strictly has to be (we could
probably get around with 95 characters), but at this point, you're
reaching into edge case territory anyway, and I'd rather have a little
too much wiggle room here.
This PR removes the last two flags related to the project managament
improvements project, making the new project creation form GA.
In doing so, we can also delete the old project creation form (or at
least the page, the form is still in use in the project settings).
This PR:
- adds a flag to anonymize user emails in the new project cards
- performs the anonymization using the existing `anonymise` function
that we have.
It does not anonymize the system user, nor does it anonymize groups. It
does, however, leave the gravatar url unchanged, as that is already
hashed (but we may want to hide that too).
This PR also does not affect the user's name or username. Considering
the target is the demo instance where the vast majority of users don't
have this (and if they do, they've chosen to set it themselves), this
seems an appropriate mitigation.
With the flag turned off:

With the flag on:

Fix project role assignment for users with `ADMIN` permission, even if
they don't have the Admin root role. This happens when e.g. users
inherit the `ADMIN` permission from a group root role, but are not
Admins themselves.
---------
Co-authored-by: Gastón Fournier <gaston@getunleash.io>
This PR adds metrics tracking for:
- "maxConstraintValues": the highest number of constraint values that
are in use
- "maxConstraintsPerStrategy": the highest number of constraints used on
a strategy
It updates the existing feature strategy read model that returns max
metrics for other strategy-related things.
It also moves one test into a more fitting describe block.
Instead of running exists on every row, we are joining the exists, which
runs the query only once.
This decreased load time on my huge dataset from 2000ms to 200ms.
Also added tests that values still come through as expected.
Instead of running exists on every row, we are joining the exists, which
runs the query only once.
This decreased load time on my huge dataset from 2000ms to 200ms.
Also added tests that values still come through as expected.
**Upgrade to React v18 for Unleash v6. Here's why I think it's a good
time to do it:**
- Command Bar project: We've begun work on the command bar project, and
there's a fantastic library we want to use. However, it requires React
v18 support.
- Straightforward Upgrade: I took a look at the upgrade guide
https://react.dev/blog/2022/03/08/react-18-upgrade-guide and it seems
fairly straightforward. In fact, I was able to get React v18 running
with minimal changes in just 10 minutes!
- Dropping IE Support: React v18 no longer supports Internet Explorer
(IE), which is no longer supported by Microsoft as of June 15, 2022.
Upgrading to v18 in v6 would be a good way to align with this change.
TS updates:
* FC children has to be explicit:
https://stackoverflow.com/questions/71788254/react-18-typescript-children-fc
* forcing version 18 types in resolutions:
https://sentry.io/answers/type-is-not-assignable-to-type-reactnode/
Test updates:
* fixing SWR issue that we have always had but it manifests more in new
React (https://github.com/vercel/swr/issues/2373)
---------
Co-authored-by: kwasniew <kwasniewski.mateusz@gmail.com>
This PR removes the flag for the new project card design, making it GA.
It also removes deprecated components and updates one reference (in the
groups card) to the new components instead.
## About the changes
Removes the deprecated state endpoint, state-service (despite the
service itself not having been marked as deprecated), and the file
import in server-impl. Leaves a TODO in place of where file import was
as traces for a replacement file import based on the new import/export
functionality
## About the changes
This aligns us with the requirement of having ip in all events. After
tackling the enterprise part we will be able to make the ip field
mandatory here:
2c66a4ace4/src/lib/types/events.ts (L362)
In preparation for v6, this PR removes usage and references to
`error.description` instead favoring `error.message` (as mentioned
#4380)
I found no references in the front end, so this might be (I believe it
to be) all the required changes.
This PR is part of #4380 - Remove legacy `/api/feature` endpoint.
## About the changes
### Frontend
- Removes the useFeatures hook
- Removes the part of StrategyView that displays features using this
strategy (not been working since v4.4)
- Removes 2 unused features entries from routes
### Backend
- Removes the /api/admin/features endpoint
- Moves a couple of non-feature related tests (auth etc) to use
/admin/projects endpoint instead
- Removes a test that was directly related to the removed endpoint
- Moves a couple of tests to the projects/features endpoint
- Reworks some tests to fetch features from projects features endpoint
and strategies from project strategies
1. Added new schema and tests
2. Controller also accepts the data
3. Also sending fake data from frontend currently
Next steps, implement service/store layer and frontend
Now we are also sending project id to prometheus, also querying from
database. This sets us up for grafana dashboard.
Also put the metrics behind flag, just incase it causes cpu/memory
issues.
This PR updates the project service to automatically create a project id
if it is not provided. The feature is behind a flag. If an ID is
provided, it will still attempt to use that ID instead.
This PR adds a function to automatically generate a project ID on
creation. Using this when the id is missing will be handled in following
PRs.
The function uses the existing `slug` package to create a slug, and then
takes the 12 characters of a uuidv4 string to generate an ID.
The included tests check that the 12 character hash is added and that
the resulting string is url friendly (by checking that
`encodeURIComponent` doesn't change it).
We could also test a lot of edge cases (such as dealing with double
spaces, trimming the string, etc), but I think that's better handled by
the library itself (but you can check out what I removed in
2d9bcb6390
for an idea).
The function doesn't really need to be in the service; it could be moved to a util. But for proximity, I'll create it here first.
Final rank has always been ordering correctly by default. But after 5.12
I see some issues that sometimes it is not ordered. Just to be extra
sure, I am for ordering it.
This PR removes the workaround introduced in
https://github.com/Unleash/unleash/pull/6931. After
https://github.com/ivarconr/unleash-enterprise/pull/1268 has been
merged, this should be safe to apply.
Notably, this PR:
- tightens up the type for the enable change request function, so we can
use that to inform the code
- skips trying to do anything with an empty array
The last point is less important than it might seem because both the env
validation and the current implementation of the callback is essentially
a no-op when there are no envs. However, that's hard to enforce. If we
just exit out early, then at least we know nothing happens.
Optionally, we could do something like this instead, but I'm not sure
it's better or worse. Happy to take input.
```ts
const crEnvs = newProject.changeRequestEnvironments ?? []
await this.validateEnvironmentsExist(crEnvs.map((env) => env.name));
const changeRequestEnvironments =
await enableChangeRequestsForSpecifiedEnvironments(crEnvs,);
data.changeRequestEnvironments = changeRequestEnvironments;
```
This PR improves the handling of change request enables on project
creation in two ways:
1. We now verify that the envs you try to enable CRs for exist before
passing them on to the enterprise functionality.
2. We include data about environments and change request environments in
the project created events.
This commit adds an `environments` property to the project created
payload. The list contains only the projects that the project has
enabled.
The point of adding it is that it gives you a better overview over
what you have created.
## About the changes
This PR removes the feature flag `queryMissingTokens` that was fully
rolled out.
It introduces a new way of checking edgeValidTokens controlled by the
flag `checkEdgeValidTokensFromCache` that relies in the cached data but
hits the DB if needed.
The assumption is that most of the times edge will find tokens in the
cache, except for a few cases in which a new token is queried. From all
tokens we expect at most one to hit the DB and in this case querying a
single token should be better than querying all the tokens.
I've tried to use/add the audit info to all events I could see/find.
This makes this PR necessarily huge, because we do store quite a few
events.
I realise it might not be complete yet, but tests
run green, and I think we now have a pattern to follow for other events.
This PR adds an optional function parameter to the `createProject`
function that is intended to enable change requests for the newly
created project.
The assumption is that all the logic within will be decided in the
enterprise impl. The only thing we want to verify here is that it is
called after the project has been created.
This PR adds functionality to the `createProject` function to choose
which environments should be enabled when you create a new project. The
new `environments` property is optional and omitting it will make it
work exactly as it does today.
The current implementation is fairly strict. We have some potential
ideas to make it easier to work with, but we haven't agreed on any yet.
Making it this strict means that we can always relax the rules later.
The rules are (codified in tests):
- If `environments` is not provided, all non-deprecated environments are
enabled
- If `environments` is provided, only the environments listed are
enabled, regardless of whether they're deprecated or not
- If `environments` is provided and is an empty array, the service
throws an error. The API should dilsallow that via the schema anyway,
but this catches it in case it sneaks in some other way.
- If `environments` is provided and contains one or more environments
that don't exist, the service throws an error. While we could ignore
them, that would lead to more complexity because we'd have to also check
that the at least one of the environments is valid. It also leads to
silent ignoring of errors, which may or may not be good for the user
experience.
The API endpoint for this sits in enterprise, so no customer-facing
changes are part of this.
Previously, we were not validating that the ID was a number, which
sometimes resulted in returning our database queries (source code) to
the frontend. Now, we have validation middleware.
Previously, we were extracting the project from the token, but now we
will retrieve it from the session, which contains the full list of
projects.
This change also resolves an issue we encountered when the token was a
multi-project token, formatted as []:dev:token. Previously, it was
unable to display the exact list of projects. Now, it will show the
exact project names.
<details>
<summary>Feature Flag Cleanup</summary>
| Stale Flag | Value |
| ---------- | ------- |
| stripClientHeadersOn304 | true |
</details>
<details>
<summary>Trigger</summary>
https://github.com/Unleash/unleash/issues/6559#issuecomment-2058848984
</details>
<details>
<summary>Bot Commands</summary>
`@gitar-bot cleanup stale_flag=value` will cleanup a stale feature flag.
Replace `stale_flag` with the name of the stale feature flag and `value`
with either `true` or `false`.
</details>
---------
Co-authored-by: Gitar Bot <noreply@gitar.co>
## About the changes
- Removes the feature flag for the created_by migrations.
- Adds a configuration option in IServerOption for
`ENABLE_SCHEDULED_CREATED_BY_MIGRATION` that defaults to `false`
- the new configuration option when set on startup enables scheduling of
the two created_by migration services (features+events)
- Removes the dependency on flag provider in EventStore as it's no
longer needed
- Adds a brief description of the new configuration option in
`configuring-unleash.md`
- Sets the events created_by migration interval to 15 minutes, up from
2.
---------
Co-authored-by: Gastón Fournier <gaston@getunleash.io>
## About the changes
This PR provides a service that allows a scheduled function to run in a
single instance. It's currently not in use but tests show how to wrap a
function to make it single-instance:
65b7080e05/src/lib/features/scheduler/job-service.test.ts (L26-L32)
The key `'test'` is used to identify the group and most likely should
have the same name as the scheduled job.
---------
Co-authored-by: Christopher Kolstad <chriswk@getunleash.io>
This PR expands upon #6773 by returning the list of removed properties
in the API response. To achieve this, I added a new top-level `warnings`
key to the API response and added an `invalidContextProperties` property
under it. This is a list with the keys that were removed.
## Discussion points
**Should we return the type of each removed key's value?** We could
expand upon this by also returning the type that was considered invalid
for the property, e.g. `invalidProp: 'object'`. This would give us more
information that we could display to the user. However, I'm not sure
it's useful? We already return the input as-is, so you can always
cross-check. And the only type we allow for non-`properties` top-level
properties is `string`. Does it give any useful info? I think if we want
to display this in the UI, we might be better off cross-referencing with
the input?
**Can properties be invalid for any other reason?** As far as I can
tell, that's the only reason properties can be invalid for the context.
OpenAPI will prevent you from using a type other than string for the
context fields we have defined and does not let you add non-string
properties to the `properties` object. So all we have to deal with are
top-level properties. And as long as they are strings, then they should
be valid.
**Should we instead infer the diff when creating the model?** In this
first approach, I've amended the `clean-context` function to also return
the list of context fields it has removed. The downside to this approach
is that we need to thread it through a few more hoops. Another approach
would be to compare the input context with the context used to evaluate
one of the features when we create the view model and derive the missing
keys from that. This would probably work in 98 percent of cases.
However, if your result contains no flags, then we can't calculate the
diff. But maybe that's alright? It would likely be fewer lines of code
(but might require additional testing), although picking an environment
from feels hacky.
Don't include invalid context properties in the contexts that we
evaluate.
This PR removes any non-`properties` fields that have a non-string
value.
This prevents the front end from crashing when trying to render an
object.
Expect follow-up PRs to include more warnings/diagnostics we can show to
the end user to inform them of what fields have been removed and why.
Via the API you can currently create gradualRollout strategies without
any parameters set, when visiting the UI afterwards, you can edit this,
because the UI reads the parameter list from the database and sees that
some parameters are required, and refuses to accept the data. This PR
adds defaults for gradualRollout strategies created from the API, making
sure gradual rollout strategies always have `rollout`, `groupId` and
`stickiness` set.
Provides store method for retrieving traffic usage data based on
period parameter, and UI + ui hook with the new chart for displaying
traffic usage data spread out over selectable month.

In this PR we copied and adapted a plugin written by DX for highlighting
a column in the chart:

There are some minor improvements planned which will come in a separate
PR, reversing the order in legend and tooltip so the colors go from
light to dark, and adding a month -sum below the legend
## Discussion points
- Should any of this be extracted as a separate reusable component?
---------
Co-authored-by: Nuno Góis <github@nunogois.com>
## About the changes
There seems to be a typo in the authorization header. We're keeping the
old typo as preferred just in case, but if not present we'll default to
the authorization header (not authorisation).
Not sure about the impact of this bug, as all registrations might be
using default project.
## About the changes
We see some logs with: `Failed to store events: Error: The query is
empty` which suggests we're not sending events to batchStore. This will
help us confirm that and will give us better insights
{kind=link}